Kafka Brokers, Clusters, and Replication Explained
Understanding the Distributed Architecture Behind Kafka Reliability and Scalability
One of the biggest reasons:
Apache Kafka
became the backbone of modern event-driven systems is because Kafka was designed from the ground up as a:
Distributed system.
Kafka is not just:
- a queue
- a single server
- a messaging tool
It is a distributed event streaming platform built for:
- scalability
- fault tolerance
- high availability
- durability
- massive throughput
To achieve this, Kafka relies heavily on:
- brokers
- clusters
- partitions
- replication
- leader election
These concepts form the operational foundation of Kafka.
In this article, we will deeply explore:
- Kafka brokers
- Kafka clusters
- distributed storage
- replication
- leader and follower replicas
- failover handling
- high availability
- data durability
- why Kafka scales so effectively
Understanding these concepts is essential before moving into production Kafka engineering.
Why Kafka Needed a Distributed Architecture
Modern systems generate enormous amounts of data.
Examples:
- payment transactions
- clickstreams
- fraud detection events
- IoT telemetry
- observability metrics
- streaming analytics
A single server quickly becomes insufficient because of:
- storage limits
- CPU bottlenecks
- network saturation
- fault tolerance risks
Kafka solved this by distributing workload across multiple servers.
The Big Picture
At a high level:
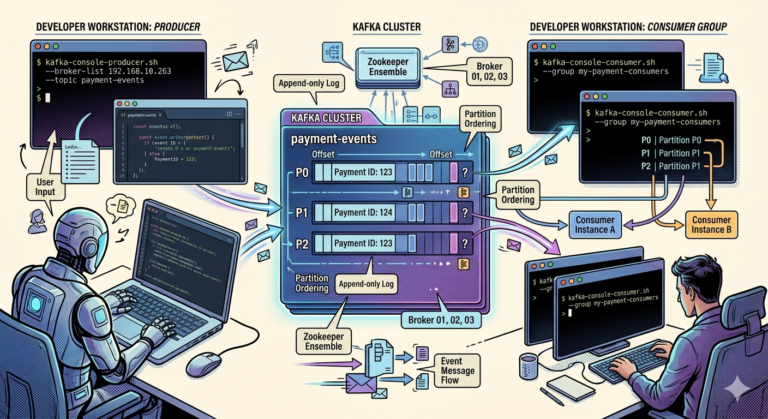
Producer
↓
Kafka Cluster
├── Broker 1
├── Broker 2
└── Broker 3
↓
Consumers
The cluster works together as a unified event streaming platform.
What is a Kafka Broker?
A broker is:
A Kafka server responsible for storing and serving event data.
Each broker:
- stores partitions
- receives producer writes
- serves consumer reads
- participates in replication
- coordinates distributed storage
A Kafka deployment usually contains multiple brokers.
Simple Example
Suppose you have:
Broker 1
Broker 2
Broker 3
Together they form:
A Kafka cluster.
Events distribute across these brokers automatically.
Why Multiple Brokers Matter
Multiple brokers provide:
- scalability
- redundancy
- fault tolerance
- distributed processing
Without multiple brokers:
- Kafka becomes a single point of failure
- scalability becomes limited
What is a Kafka Cluster?
A Kafka cluster is:
A group of brokers working together.
The cluster appears as a single logical platform to:
- producers
- consumers
- applications
Internally:
- partitions distribute across brokers
- replicas synchronize continuously
- leaders coordinate writes
Kafka Topics Are Distributed Across Brokers
Recall that:
- topics contain partitions
Example:
payments topic
├── Partition 0
├── Partition 1
├── Partition 2
Kafka distributes these partitions across brokers.
Example:
Broker 1 → Partition 0
Broker 2 → Partition 1
Broker 3 → Partition 2
This enables horizontal scalability.
Why Partition Distribution is Important
Partition distribution allows Kafka to:
- spread storage load
- distribute network traffic
- parallelize reads/writes
- scale throughput
Without partition distribution:
- one broker becomes overloaded
Brokers Store Partition Logs
Each partition behaves like:
An append-only event log.
Example:
Partition 0
Offset 0 → PaymentCompleted
Offset 1 → PaymentRefunded
Offset 2 → FraudDetected
The assigned broker physically stores this data.
Kafka is a Distributed Log System
This is one of Kafka’s most important architectural ideas.
Kafka is fundamentally:
A distributed append-only log platform.
This design enables:
- replayability
- scalability
- durability
- efficient sequential writes
The Problem of Broker Failure
Now consider a critical question:
What happens if a broker crashes?
Suppose:
Broker 1 fails
If Broker 1 stored unique data:
- events become unavailable
- data may be lost
- consumers fail
Kafka solves this using:
Replication.
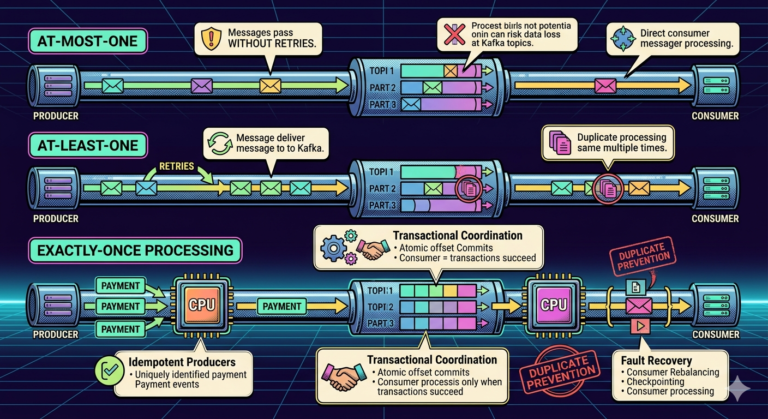
What is Replication?
Replication means:
Kafka copies partition data across multiple brokers.
Example:
Partition 0
├── Broker 1
├── Broker 2
└── Broker 3
Now:
- multiple brokers contain the same partition data
This dramatically improves reliability.
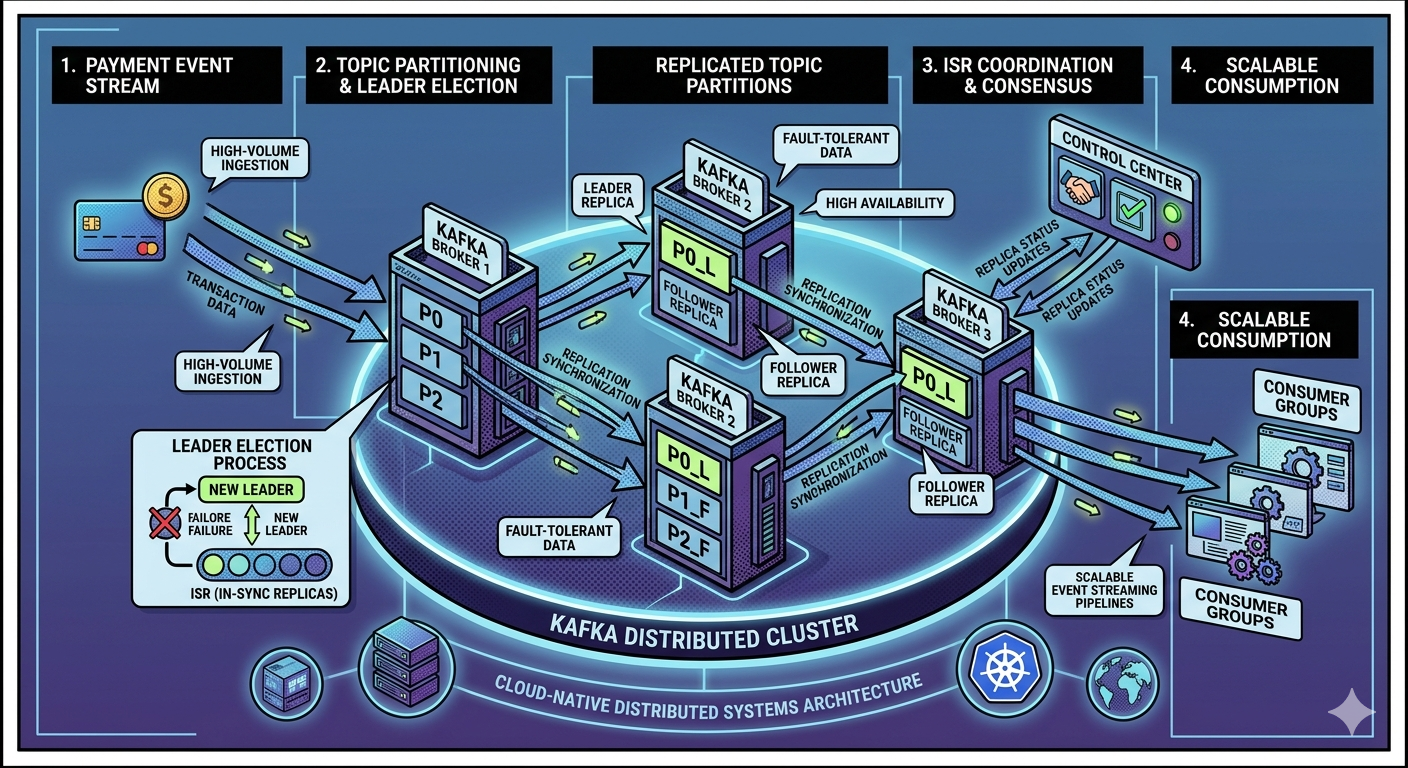
Replication Factor
Kafka replication is controlled using:
Replication Factor.
Example:
Replication Factor = 3
means:
- 3 copies of partition data exist
Example Architecture
Partition 0
├── Leader Replica → Broker 1
├── Follower Replica → Broker 2
└── Follower Replica → Broker 3
Kafka continuously synchronizes these replicas.
Leader and Follower Replicas
Every partition has:
- one leader replica
- zero or more follower replicas
Leader Replica
The leader handles:
- producer writes
- consumer reads
- partition coordination
All traffic goes through the leader.
Follower Replicas
Followers:
- copy data from leader
- stay synchronized
- act as backups
Followers do not normally serve client traffic.
Why Kafka Uses Leaders
Leader-based architecture simplifies:
- consistency
- ordering
- coordination
- replication management
Without leaders:
- distributed writes become much more complex
In-Sync Replicas (ISR)
Kafka tracks replicas that remain fully synchronized.
These are called:
In-Sync Replicas (ISR)
ISR replicas:
- are fully caught up
- can safely become leaders
Example ISR
Partition 0
├── Broker 1 → Leader
├── Broker 2 → ISR
└── Broker 3 → ISR
All replicas contain identical data.
What Happens During Replication?
Suppose producer sends:
{
"eventType": "PaymentCompleted"
}
Flow:
Producer
↓
Leader Replica
↓
Follower Replicas
Followers continuously copy leader updates.
Why Replication Matters
Replication provides:
- durability
- fault tolerance
- high availability
- disaster recovery
Without replication:
- broker failure risks data loss
What Happens if Leader Broker Fails?
Suppose:
Broker 1 crashes
Kafka automatically:
- selects another ISR replica
- promotes it to leader
Example:
Broker 2 becomes new leader
This process is called:
Leader election.
Leader Election
Leader election allows Kafka to:
- recover automatically
- minimize downtime
- continue serving traffic
This is critical for production-grade systems.
Why ISR is Important During Failover
Kafka promotes only:
- synchronized replicas
Why?
Because outdated replicas could:
- lose messages
- corrupt ordering
- create inconsistencies
ISR ensures safe failover.
High Availability in Kafka
Kafka achieves high availability through:
- distributed brokers
- replication
- leader election
- ISR coordination
This allows Kafka clusters to survive:
- hardware failures
- broker crashes
- network interruptions
without major disruption.
Kafka and Durability
Kafka writes events:
- sequentially
- persistently to disk
Combined with replication:
- this creates strong durability guarantees
Kafka is often trusted for:
- financial transactions
- audit pipelines
- observability systems
- critical event storage
Rack Awareness
Large Kafka deployments may span:
- data centers
- availability zones
- cloud regions
Kafka supports:
Rack awareness.
This ensures replicas distribute across physical infrastructure.
Benefits:
- disaster resilience
- infrastructure fault isolation
Broker Scalability
Kafka clusters scale horizontally.
Need more capacity?
Add more brokers.
Example:
3 brokers → 10 brokers → 50 brokers
Kafka redistributes partitions accordingly.
Why Horizontal Scaling Matters
Horizontal scaling enables:
- increased throughput
- larger storage capacity
- higher parallelism
- distributed fault tolerance
This is why Kafka handles enormous workloads.
Real-World Example — Payment Processing Platform
Imagine:
- millions of payment events daily
- replicated across multiple Kafka brokers
- partitions distributed across cluster nodes
- consumers processing events independently
Even if:
- one broker crashes
the system continues functioning.
This resilience is one reason Kafka dominates modern event streaming.
Kafka Broker Coordination
Kafka brokers also coordinate:
- metadata
- partition leadership
- replication state
- consumer group information
Historically this coordination relied on:
- Apache Zookeeper
Modern Kafka increasingly uses:
- KRaft mode
We will explore this deeply in the next article.
Common Beginner Misconceptions
Misconception 1
Each broker stores all topic data
No.
Partitions distribute across brokers.
Misconception 2
Replication improves performance
Replication improves:
- reliability
- durability
not necessarily throughput.
Misconception 3
Followers serve consumers directly
Normally:
- consumers read from leaders
Misconception 4
Leader election causes data loss automatically
Kafka carefully manages failover using ISR.
Why This Architecture Made Kafka So Successful
Kafka’s distributed architecture combines:
- scalability
- durability
- fault tolerance
- replayability
- distributed processing
in a remarkably elegant system.
This is why:
Apache Kafka
became foundational infrastructure for modern event-driven architectures.
Key Takeaways
Kafka brokers are:
- distributed servers storing partition data
Kafka clusters:
- combine brokers into scalable event infrastructure
Replication provides:
- durability
- fault tolerance
- high availability
Leader replicas:
- handle reads/writes
Follower replicas:
- synchronize continuously for backup and failover
Together, these concepts enable Kafka to operate as:
- a scalable
- resilient
- distributed event streaming platform
capable of powering mission-critical real-time systems.