Kafka Retention, Persistence, and Replayability Explained
Why Kafka Stores Events Differently from Traditional Messaging Systems
One of the most revolutionary ideas behind:
Apache Kafka
is this:
Kafka does not immediately delete messages after consumption.
This may sound simple, but it fundamentally changes how distributed systems are designed.
Traditional messaging systems often behave like:
- temporary queues
- transient delivery channels
- short-lived message brokers
Kafka behaves differently.
Kafka treats events as:
Durable, replayable streams of history.
This design enables:
- event replay
- auditability
- recovery
- stream processing
- analytics rebuilding
- event sourcing
- machine learning retraining
In this article, we will deeply explore:
- Kafka retention
- persistence
- replayability
- log storage
- retention policies
- replay workflows
- consumer independence
- event history
- real-world architectural implications
Understanding these concepts is critical because retention and replayability are among Kafka’s most powerful capabilities.
Traditional Messaging Systems vs Kafka
Traditional queue systems often work like this:
Message Delivered
↓
Message Removed
Once consumed:
- message disappears permanently
This works for:
- temporary task queues
- transient processing
But creates limitations.
Problems with Traditional Queue Deletion
Suppose:
- analytics service crashes
- fraud algorithm improves
- downstream bug corrupts processing
If messages already disappeared:
- replay becomes impossible
- historical reconstruction becomes difficult
This limits system flexibility significantly.
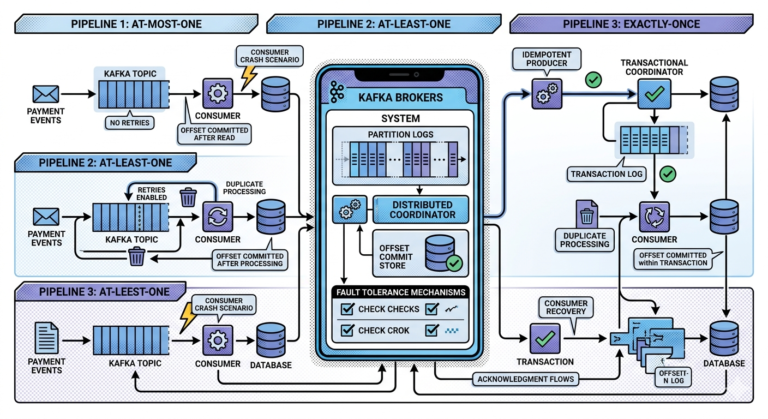
Kafka’s Different Philosophy
Kafka treats messages as:
Persistent event logs.
Instead of deleting messages immediately:
- Kafka retains them for configurable durations
Consumers track:
- their own offsets independently
This changes everything.
Kafka as an Append-Only Log
Kafka topics behave like:
Append-only distributed logs.
Example:
Offset 0 → OrderPlaced
Offset 1 → PaymentCompleted
Offset 2 → ShipmentCreated
Events remain stored even after consumption.
Why This Architecture Matters
Because now:
- multiple consumers can process independently
- consumers can replay history
- systems can recover from failures
- analytics can rebuild state
Kafka becomes:
A durable event backbone.
Understanding Persistence
Persistence means:
Kafka stores events durably on disk.
When producers publish records:
- Kafka writes them sequentially
- stores them physically
- replicates them if configured
Events survive:
- consumer restarts
- application crashes
- temporary outages
Kafka Stores Events on Disk
Unlike purely in-memory systems:
- Kafka persists records to disk
This provides:
- durability
- reliability
- recovery capability
Combined with replication:
- Kafka becomes highly resilient.
Sequential Disk Writes
Kafka uses:
Sequential append-only writes.
Example:
Offset 1000
Offset 1001
Offset 1002
Sequential writes are extremely efficient.
This contributes heavily to Kafka’s:
- high throughput
- scalability
What is Retention?
Retention defines:
How long Kafka keeps records.
Kafka retains messages based on:
- time
- size
- policy configuration
Time-Based Retention
Example:
Keep events for 7 days
After 7 days:
- Kafka removes older segments
Size-Based Retention
Example:
Keep maximum 500 GB
Older records deleted when limit exceeded.
Why Retention Exists
Infinite storage is impractical.
Retention policies balance:
- replay capability
- storage cost
- operational needs
Kafka Retention Is Topic-Level
Different topics may use different policies.
Examples:
| Topic | Retention |
|---|---|
| payments | 90 days |
| logs | 7 days |
| metrics | 24 hours |
| audit-events | 1 year |
Retention depends on business requirements.
Consumer Independence Changes Everything
In Kafka:
- consumers track offsets independently
Example:
Fraud Consumer → Offset 1000
Analytics Consumer → Offset 800
Audit Consumer → Offset 200
Kafka does not delete records after one consumer finishes.
This is fundamentally different from traditional queues.
Replayability — Kafka’s Superpower
Replayability means:
Consumers can re-read historical events.
Example:
Read from Offset 0 again
Kafka allows:
- complete event replay
This is incredibly powerful.
Real-World Example — Analytics Bug
Suppose:
- analytics service miscalculates revenue
- bug discovered later
Traditional queue:
- historical data gone
Kafka:
- replay historical events
- rebuild analytics correctly
Massive operational advantage.
Real-World Example — Fraud Detection
Suppose fraud model improves.
Organization can:
- replay months of transactions
- retrain algorithms
- detect previously missed fraud patterns
This capability is transformative.
Event Replay Workflow
Replay process:
Consumer resets offset
↓
Kafka streams historical events again
No special backup restoration required.
Kafka itself becomes:
- replay infrastructure.
Offset Resetting
Consumers can reset offsets to:
- earliest records
- latest records
- specific timestamps
- custom positions
This enables flexible replay workflows.
Example Offset Reset
kafka-consumer-groups.sh \
--reset-offsets
Consumers can restart from historical positions.
Why Replayability Matters So Much
Replayability enables:
- recovery
- debugging
- audit reconstruction
- machine learning retraining
- event sourcing
- state rebuilding
This is one reason Kafka became foundational infrastructure for modern event-driven systems.
Kafka Retention and Event Sourcing
Event sourcing architectures rely heavily on:
- durable event history
Kafka retention naturally supports:
- immutable event logs
- replayable business history
Topics effectively become:
Historical timelines of business activity.
Kafka Retention and CQRS
CQRS systems use Kafka retention for:
- rebuilding projections
- recovering read models
- synchronizing distributed state
Replayability becomes critical for resilience.
Segment Files in Kafka
Internally Kafka stores logs using:
Segment files.
Instead of one enormous file:
- logs split into manageable chunks
Example:
payments-0.log
payments-1.log
payments-2.log
This improves:
- storage management
- cleanup efficiency
Log Compaction
Kafka also supports:
Log compaction.
Instead of deleting purely by time:
- Kafka retains latest value per key
Useful for:
- state synchronization
- changelog topics
- compacted state streams
Example of Log Compaction
Events:
User123 → ACTIVE
User123 → SUSPENDED
User123 → ACTIVE
Compacted log may retain:
- latest state only
while still preserving stream semantics.
Why Log Compaction Exists
Compaction enables:
- efficient state recovery
- smaller storage footprint
- fast bootstrap of distributed services
Widely used in:
- Kafka Streams
- stateful applications
Kafka Retention vs Database Storage
Kafka is NOT typically a replacement for:
- transactional databases
Kafka retention is optimized for:
- event streams
- append-only history
- replay workflows
Databases still handle:
- relational queries
- transactional integrity
- random updates
Event History Becomes Extremely Valuable
Organizations increasingly realize:
Historical event streams are strategic assets.
Historical streams enable:
- behavioral analytics
- forensic analysis
- AI model training
- operational debugging
Kafka makes this practical at scale.
Real-World Example — Ride Sharing
Ride-sharing platforms may replay:
- trip events
- driver activity
- surge pricing history
to:
- rebuild models
- analyze demand
- retrain algorithms
Kafka retention enables this.
Real-World Example — Observability
Observability platforms stream:
- logs
- metrics
- traces
Kafka retention allows:
- historical troubleshooting
- outage reconstruction
- anomaly analysis
Storage Tradeoffs
Long retention increases:
- storage costs
- infrastructure requirements
Organizations must balance:
- replay value
- operational expense
Retention design becomes strategic.
Infinite Retention?
Technically possible.
Practically expensive.
Some organizations archive:
- older Kafka data
- to object storage systems
Examples:
- Amazon S3
- data lakes
- Hadoop clusters
Kafka Replay and Idempotency
Replaying events may re-trigger processing.
Applications often require:
Idempotent consumers.
Without idempotency:
- replay may duplicate side effects
Critical architectural consideration.
Retention Does Not Mean Infinite Memory
Kafka retention has limits:
- disk capacity
- infrastructure budgets
- operational policies
Retention configuration requires careful planning.
Why Kafka Replayability Is Revolutionary
Traditional systems think:
Messages are temporary
Kafka thinks:
Events are durable historical streams
This shift fundamentally changed distributed system architecture.
Common Beginner Misconceptions
Misconception 1
Kafka deletes records immediately after consumption
Consumers track offsets independently.
Misconception 2
Replay means restoring backups
Kafka replay works directly from retained logs.
Misconception 3
Kafka retention is only for debugging
Retention powers:
- analytics
- event sourcing
- AI training
- state rebuilding
Misconception 4
Kafka is just a queue
Kafka is a durable distributed event log platform.
Why Retention and Replayability Matter So Much
Retention transforms Kafka into:
- an event history platform
- a replay engine
- a distributed audit log
- a scalable streaming backbone
This capability is one of the main reasons:
Apache Kafka
became foundational infrastructure for modern:
- event-driven systems
- streaming architectures
- real-time analytics platforms
Key Takeaways
Kafka stores events as:
- durable append-only logs
Unlike traditional queues:
- Kafka retains records after consumption
Retention policies control:
- how long records remain available
Replayability enables:
- historical reprocessing
- debugging
- analytics rebuilding
- event sourcing
- machine learning retraining
Kafka consumers independently track offsets, allowing:
- multiple replay strategies
- asynchronous processing
- resilient distributed workflows
These capabilities make:
Apache Kafka
far more than a messaging system — Kafka becomes a scalable distributed event history platform.