Event Sourcing Explained with Kafka
Storing Business History as Immutable Events
Traditional applications usually store:
Current state.
For example, a banking system may store:
Account Balance = ₹45,000
But an important question arises:
How did the balance become ₹45,000?
Traditional systems often struggle to answer:
- what happened earlier
- who changed state
- when updates occurred
- how workflows evolved over time
Modern distributed systems increasingly solve this using:
Event Sourcing.
And one of the most powerful platforms for implementing event sourcing is:
Apache Kafka
Event sourcing fundamentally changes how systems think about data.
Instead of storing:
- only current state
systems store:
- the complete history of events.
In this article, we will deeply explore:
- what event sourcing is
- why it exists
- immutable event logs
- rebuilding state from events
- Kafka as an event store
- replayability
- auditability
- CQRS integration
- real-world examples
- advantages and tradeoffs
Event sourcing is one of the most important architectural patterns in modern event-driven systems.
Traditional State-Based Systems
Most applications store:
Latest state only.
Example database table:
| Account ID | Balance |
|---|---|
| ACC100 | ₹45,000 |
This tells us:
- current balance
But not:
- transaction history
- sequence of operations
- state evolution
Problems with Traditional State Storage
Traditional systems often struggle with:
- auditing
- debugging
- replaying workflows
- recovering historical state
- understanding business timelines
Example:
Why did balance become negative yesterday?
The answer may be difficult to reconstruct.
Event Sourcing Changes the Model
Event sourcing stores:
Every state-changing event.
Instead of storing only:
Balance = ₹45,000
system stores:
₹10,000 Deposited
₹2,000 Withdrawn
₹15,000 Deposited
₹3,000 Transfer
Current state becomes:
A result of event history.
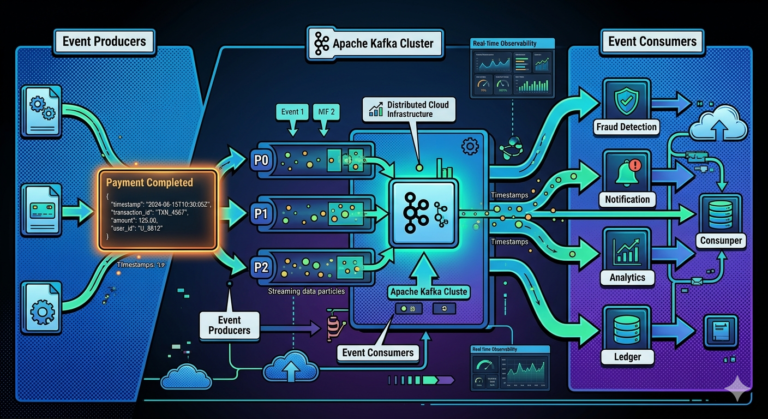
What is an Event?
An event represents:
Something that already happened.
Examples:
OrderPlaced
PaymentCompleted
FundsTransferred
InventoryReserved
ShipmentCreated
Events are:
- immutable
- historical facts
- append-only records
The Core Principle of Event Sourcing
Instead of:
Store current state
Event sourcing says:
Store all events
Then reconstruct current state whenever needed.
Understanding Immutable Events
Events should never change.
Example:
{
"eventType": "FundsDeposited",
"accountId": "ACC100",
"amount": 5000
}
Once recorded:
- event remains permanent
This creates:
- strong auditability
- historical traceability
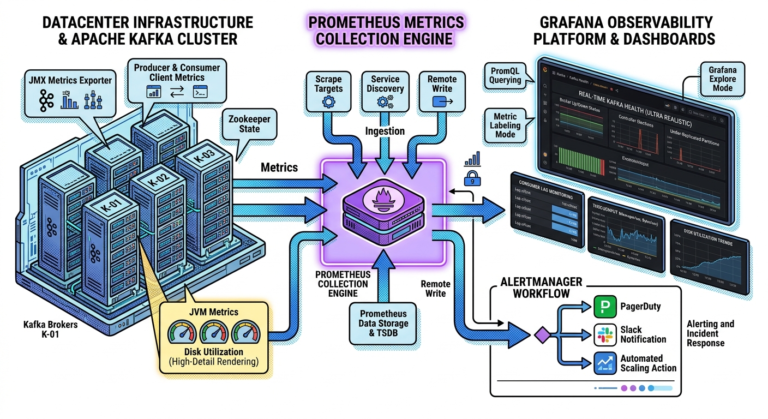
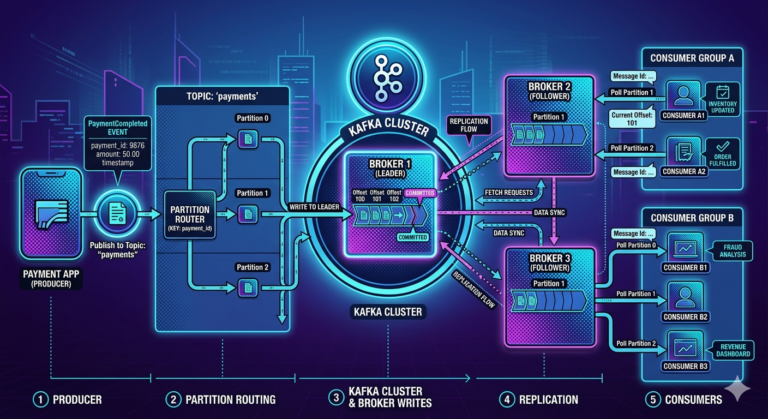
Kafka Fits Naturally with Event Sourcing
Kafka is fundamentally:
A distributed append-only event log.
This aligns perfectly with event sourcing principles.
Kafka topics naturally store:
- ordered event histories
- immutable streams
- replayable logs
Kafka as an Event Store
In event sourcing architectures:
Apache Kafka
often acts as:
The central event store.
Workflow:
Application Action
↓
Event Generated
↓
Kafka Topic
↓
Consumers Build State
Kafka durably stores all business events.
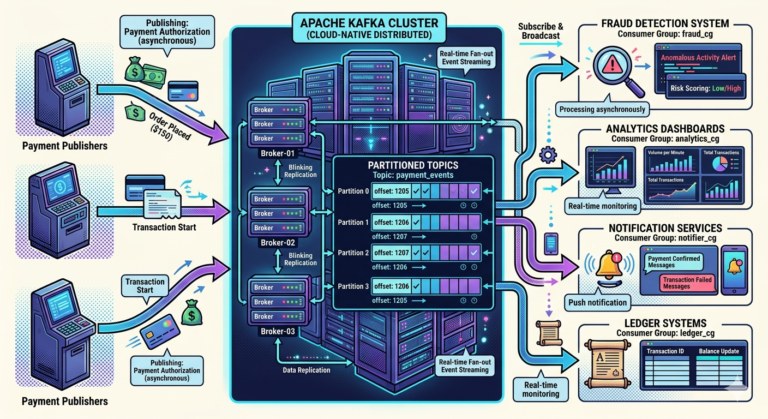
Real-World Banking Example
Suppose customer performs actions:
Deposit ₹10,000
Withdraw ₹2,000
Deposit ₹5,000
Kafka topic stores:
FundsDeposited
FundsWithdrawn
FundsDeposited
Balance becomes:
Computed state derived from events.
State Reconstruction
To rebuild account balance:
Start at ₹0
+ ₹10,000
- ₹2,000
+ ₹5,000
Final balance:
₹13,000
This process is called:
Event replay.
Why Replayability Matters
Replayability enables:
- debugging
- recovery
- analytics rebuilding
- historical simulation
- machine learning retraining
This is one of event sourcing’s greatest strengths.
Example — Fraud Detection Replay
Suppose fraud algorithm improves.
Organization may:
- replay historical payment events
- re-run fraud analysis
- detect patterns missed previously
Traditional systems struggle with this capability.
Event Logs Become the Source of Truth
In event sourcing:
Events are the source of truth
Current state becomes:
- a derived representation
This is a major conceptual shift.
Understanding Event Streams
Kafka topics become:
Streams of business history.
Example:
payments topic
├── PaymentInitiated
├── PaymentCompleted
├── RefundIssued
└── FraudDetected
The topic itself represents:
- the business timeline
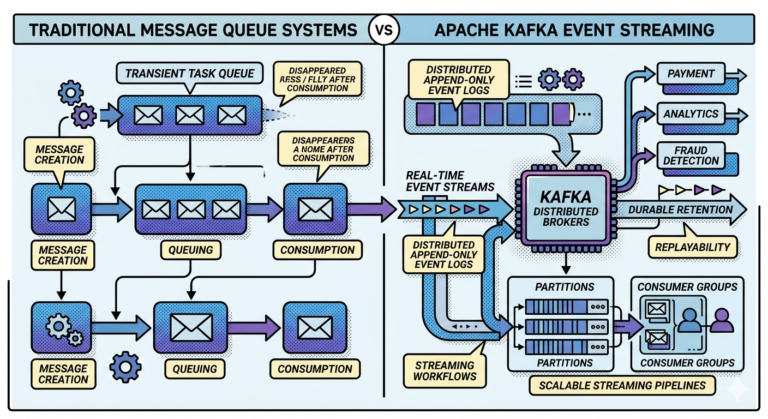
Append-Only Architecture
Kafka events are:
- appended sequentially
- never overwritten
This creates:
- durability
- ordering
- historical traceability
Why Append-Only Systems Scale Well
Append-only systems avoid:
- expensive updates
- random writes
- locking overhead
Sequential writes are extremely efficient.
This contributes heavily to Kafka’s scalability.
CQRS and Event Sourcing Together
Event sourcing is frequently combined with:
CQRS.
Workflow:
Commands
↓
Events Stored in Kafka
↓
Read Projections Updated
Events drive:
- query models
- analytics views
- dashboards
- search indexes
Materialized Views
Because rebuilding state repeatedly can be expensive, systems often maintain:
Materialized views.
These are:
- precomputed state representations
built from event streams.
Example Materialized View
Event stream:
OrderPlaced
PaymentCompleted
ShipmentCreated
Projection generates:
CustomerOrderSummary
for fast querying.
Snapshotting
Long event histories can become expensive to replay entirely.
Systems often use:
Snapshots.
Example:
Snapshot Balance = ₹40,000
Then replay only newer events afterward.
Why Snapshotting Matters
Snapshotting improves:
- startup speed
- state recovery
- replay efficiency
Especially important for:
- long-lived aggregates
- massive event histories
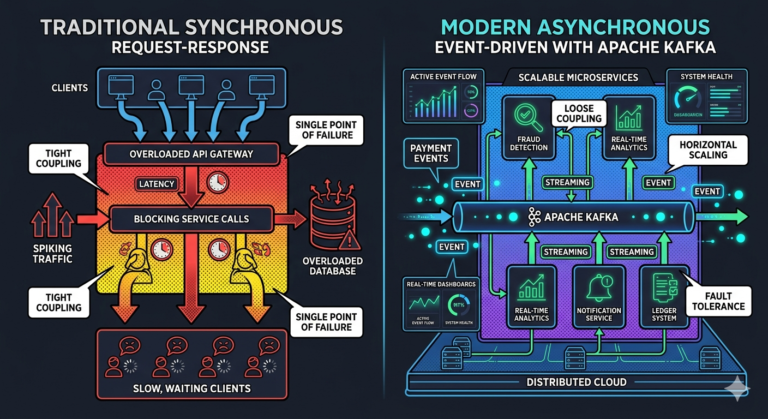
Event Sourcing in Microservices
Event sourcing naturally supports:
- microservices
- asynchronous workflows
- distributed systems
Each service reacts to:
- immutable event streams
rather than shared databases.
Real-World Example — E-Commerce
Suppose customer places order.
Events:
OrderPlaced
PaymentCompleted
InventoryReserved
ShipmentCreated
Delivered
Entire business lifecycle becomes traceable.
Auditability Benefits
Event sourcing provides extremely strong:
- auditing
- compliance
- traceability
Organizations can answer:
- who changed what
- when it happened
- how workflows evolved
Critical in:
- banking
- fintech
- healthcare
- compliance-heavy industries
Time Travel Capability
Because complete history exists:
- systems can reconstruct past state
Example:
What was account balance on May 1st?
Replay events up to that timestamp.
This is extremely powerful.
Event Versioning Challenges
Over time:
- event schemas evolve
Example:
PaymentCompleted v1
PaymentCompleted v2
Systems must handle:
- backward compatibility
- schema evolution
This becomes an important operational concern.
Immutable Data Requires New Thinking
Traditional systems think:
Update existing row
Event sourcing thinks:
Append new fact
This is a fundamentally different architectural mindset.
Eventual Consistency in Event Sourcing
Event sourcing systems are often:
Eventually consistent.
Read models update asynchronously from event streams.
Temporary delays are normal.
Benefits of Event Sourcing
1. Complete Audit History
Every business change becomes traceable.
2. Replayability
Systems can:
- rebuild state
- reprocess history
- recover workflows
3. Debugging Power
Historical event timelines simplify troubleshooting.
4. Scalability
Append-only event logs scale extremely well.
5. Loose Coupling
Services communicate through events.
Challenges of Event Sourcing
Event sourcing also introduces complexity.
1. Increased Architectural Complexity
Requires:
- event modeling
- projections
- replay handling
- versioning strategies
2. Event Schema Evolution
Managing event compatibility becomes important.
3. Eventual Consistency
Read models may lag behind writes.
4. Storage Growth
Historical events accumulate continuously.
Retention planning becomes important.
When Event Sourcing Is Worth It
Event sourcing is valuable when systems require:
- auditability
- replayability
- workflow traceability
- distributed event-driven architectures
- real-time streaming
Simple CRUD systems often do not need event sourcing.
Why Kafka Became Central to Event Sourcing
Apache Kafka
naturally supports event sourcing because it provides:
- append-only logs
- replayability
- partitioned ordering
- durable storage
- distributed scalability
Kafka topics effectively become:
Distributed business history logs.
Common Beginner Misconceptions
Misconception 1
Event sourcing stores only logs
Events become the primary source of truth.
Misconception 2
Current state disappears
State still exists through projections and snapshots.
Misconception 3
Kafka automatically creates event sourcing architecture
Event sourcing requires deliberate application design.
Misconception 4
Event sourcing is always better
It introduces substantial complexity.
Why Event Sourcing Became So Important
Modern distributed systems increasingly require:
- traceability
- replayability
- auditability
- asynchronous workflows
- scalable event processing
Event sourcing addresses these needs elegantly using:
Apache Kafka
as the durable distributed event backbone.
Key Takeaways
Event sourcing stores:
- immutable business events
instead of: - only current state
Kafka topics naturally support event sourcing through:
- append-only logs
- replayability
- durable event streams
- partitioned ordering
Current state becomes:
- derived from historical events
This architecture enables:
- auditing
- debugging
- workflow replay
- historical reconstruction
- scalable event-driven systems
Event sourcing is often combined with:
- CQRS
- projections
- snapshots
- asynchronous workflows
to build highly scalable and traceable distributed systems.