Monitoring Kafka with Prometheus and Grafana
Building Real-Time Observability Dashboards for Kafka Clusters
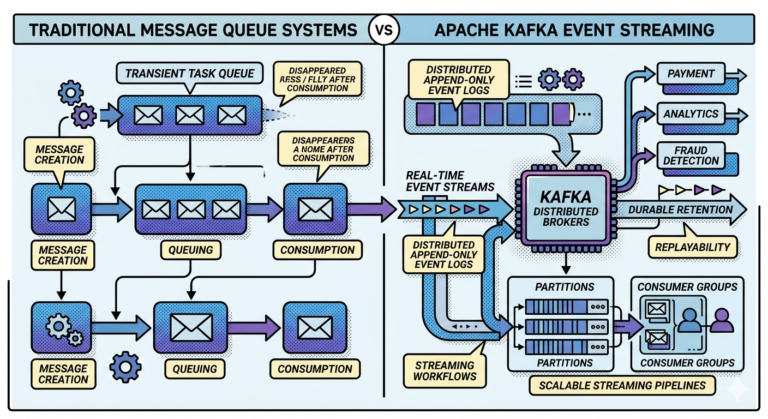
Running:
Apache Kafka
in production is not just about:
- producers
- consumers
- topics
- brokers
Operating Kafka reliably at scale requires:
Deep observability.
Kafka clusters often power:
- payment systems
- fraud detection pipelines
- real-time analytics
- streaming platforms
- critical business workflows
When Kafka becomes unhealthy:
- dashboards become stale
- fraud alerts get delayed
- payment pipelines slow down
- consumers fall behind
- event-driven systems begin failing
This is why modern Kafka deployments heavily rely on:
Prometheus
and
Grafana
to monitor:
- broker health
- consumer lag
- throughput
- replication status
- JVM metrics
- disk utilization
- cluster stability
In this article, we will deeply explore:
- Kafka monitoring architecture
- Prometheus fundamentals
- Grafana dashboards
- JMX metrics
- Kafka Exporters
- consumer lag monitoring
- broker observability
- alerting strategies
- real-world operational practices
This article introduces practical production-grade Kafka monitoring.
Why Kafka Monitoring Is Essential
Kafka systems are:
- distributed
- asynchronous
- highly concurrent
Failures are often:
- indirect
- gradual
- difficult to notice immediately
Without monitoring:
- problems accumulate silently.
Example Kafka Failure
Suppose:
- payment traffic spikes suddenly
Possible consequences:
- brokers overloaded
- consumer lag increases
- replication slows
- disk usage grows rapidly
Without observability:
- teams may detect issue too late.
Kafka Monitoring Goals
Kafka monitoring helps teams:
- maintain reliability
- detect bottlenecks
- identify failures
- scale infrastructure
- optimize performance
Monitoring is critical for:
Production readiness.
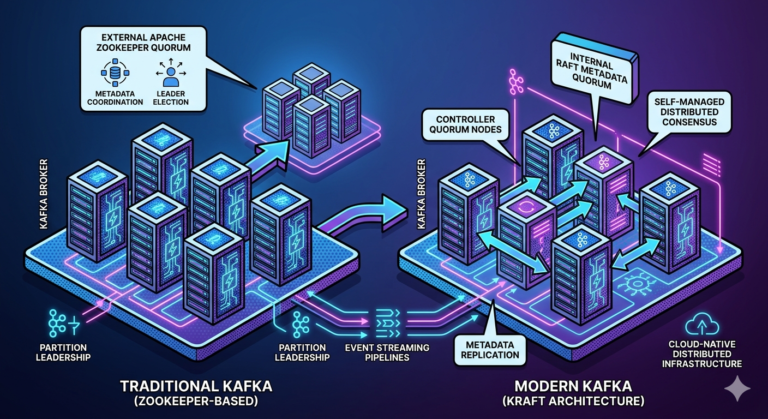
The Kafka Monitoring Stack
A very common Kafka observability architecture:
Kafka Cluster
↓
JMX Metrics
↓
Prometheus
↓
Grafana Dashboards
This combination has become:
Industry standard for Kafka observability.
What is Prometheus?
Prometheus
is:
A time-series monitoring system.
Prometheus:
- collects metrics
- stores time-series data
- evaluates alerts
- powers monitoring dashboards
Widely used in:
- cloud-native systems
- Kubernetes
- Kafka infrastructures
What is Grafana?
Grafana
is:
A visualization and dashboard platform.
Grafana connects to:
- Prometheus
- Elasticsearch
- databases
- observability tools
to display:
- dashboards
- graphs
- alerts
- operational metrics
Why Kafka Uses JMX Metrics
Kafka brokers expose metrics using:
JMX (Java Management Extensions).
Kafka itself runs on:
- JVM
JMX exposes:
- internal broker statistics
- JVM health
- request metrics
- replication status
Example Kafka JMX Metrics
Kafka exposes metrics such as:
- messages per second
- request latency
- under-replicated partitions
- active controller count
- fetch request rates
These metrics become observable through Prometheus.
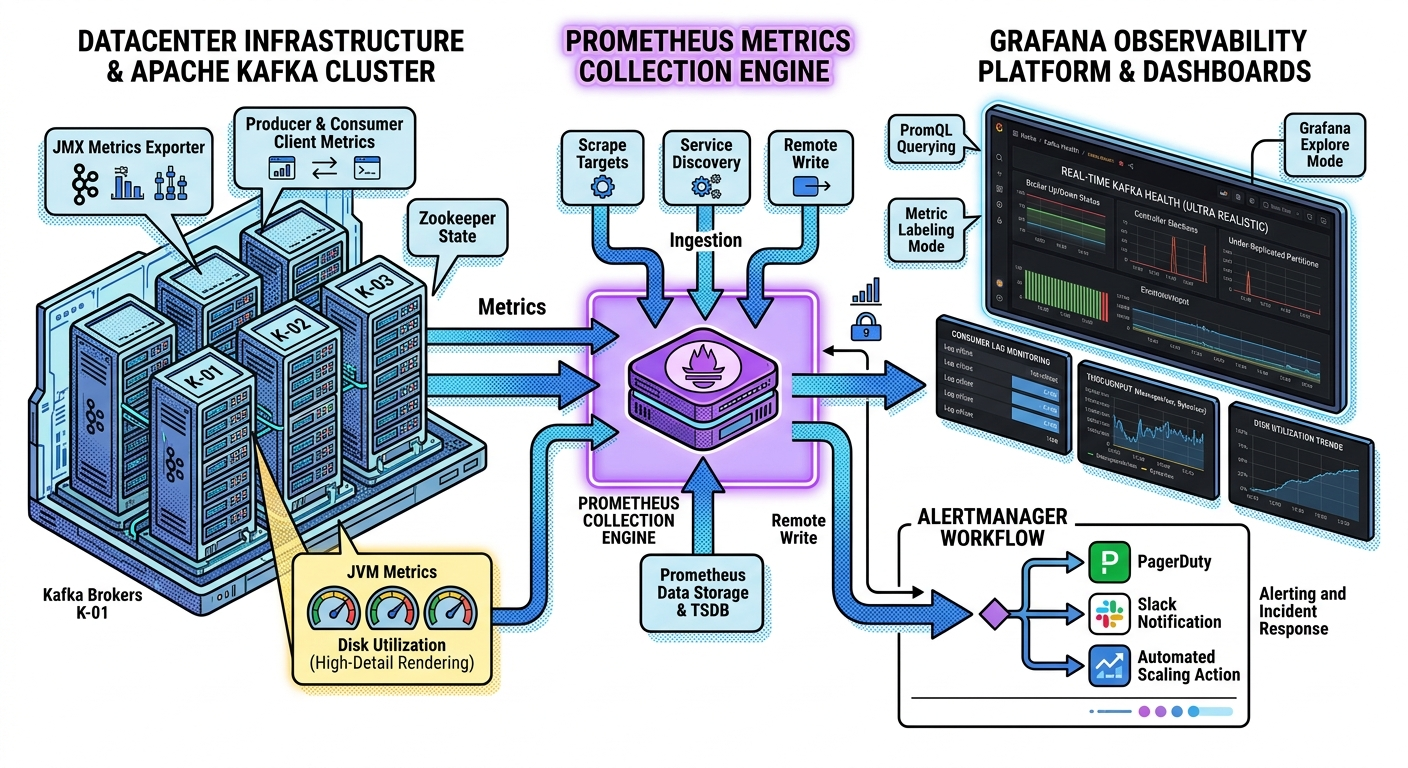
Understanding the Monitoring Pipeline
Monitoring workflow:
Kafka Broker
↓
JMX Metrics
↓
JMX Exporter
↓
Prometheus Scraping
↓
Grafana Visualization
This architecture is extremely common.
Why Prometheus Uses Scraping
Prometheus periodically:
Pulls metrics from targets.
Example:
Every 15 seconds
Prometheus requests metrics endpoints.
This is called:
Scraping.
Kafka Exporters
Kafka metrics are often exposed using:
JMX Exporter.
Common deployment:
Kafka Broker
↓
JMX Exporter Java Agent
Exporter converts:
- JMX metrics
into: - Prometheus-readable metrics.
Kafka Exporter for Consumer Lag
Many teams also use:
Kafka Exporter.
This exporter monitors:
- consumer groups
- lag metrics
- partition offsets
Consumer lag is one of the most important Kafka metrics.
High-Level Monitoring Architecture
Kafka Brokers
↓
Prometheus
↓
Grafana
↓
Dashboards & Alerts
This becomes:
- centralized operational visibility.
Important Kafka Metrics to Monitor
Kafka monitoring usually focuses on:
| Metric Category | Examples |
|---|---|
| Broker Health | CPU, memory, disk |
| Throughput | Messages/sec |
| Replication | ISR, under-replicated partitions |
| Consumer Health | Lag, throughput |
| JVM Metrics | Heap usage, GC pauses |
| Network Metrics | Request latency, socket traffic |
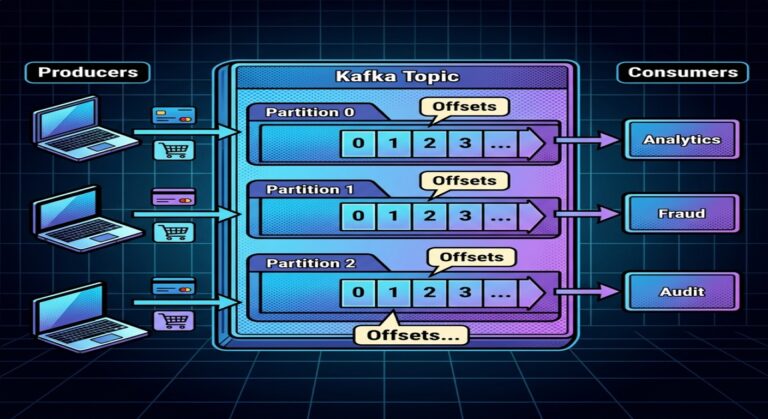
Consumer Lag Monitoring
Consumer lag measures:
Produced messages
minus
Consumed messages
High lag often indicates:
- overloaded consumers
- slow downstream systems
- insufficient partitions
Lag monitoring is critical.
Example Consumer Lag Dashboard
Grafana may display:
Consumer Group → FraudDetection
Lag → 150,000
This immediately signals:
- delayed fraud processing
Broker Throughput Monitoring
Important metrics include:
- incoming bytes/sec
- outgoing bytes/sec
- messages/sec
These reveal:
- cluster traffic patterns
- scaling requirements
Replication Health Monitoring
Kafka replication metrics include:
UnderReplicatedPartitions
If replicas fall behind:
- fault tolerance weakens
This requires immediate investigation.
ISR Monitoring
Kafka tracks:
In-Sync Replicas (ISR)
Healthy ISR indicates:
- stable replication
ISR shrinkage may indicate:
- network problems
- slow disks
- overloaded brokers
JVM Monitoring
Kafka brokers are JVM applications.
Important JVM metrics:
- heap usage
- garbage collection pauses
- thread counts
- memory pressure
Poor JVM health affects:
- broker performance
- request latency
Disk Usage Monitoring
Kafka stores:
- durable event logs
Disk monitoring is essential because:
- Kafka retention consumes large storage
Critical metrics:
- disk utilization
- segment growth
- retention cleanup rates
Why Disk Monitoring Is Critical
If brokers run out of disk:
- cluster stability collapses
- partitions fail
- producers may stop working
Disk alerts are extremely important.
Network Monitoring
Kafka clusters move:
- enormous event volumes
Network metrics include:
- request latency
- socket throughput
- connection counts
Network bottlenecks can:
- increase lag
- slow replication
Real-Time Dashboards
Grafana dashboards often visualize:
- cluster throughput
- broker health
- lag trends
- partition distribution
- JVM metrics
This provides:
Operational situational awareness.
Example Grafana Dashboard Layout
Typical dashboard sections:
Broker Health
Consumer Lag
Replication Status
Topic Throughput
Disk Utilization
JVM Metrics
Operations teams monitor these continuously.
Alerting with Prometheus
Prometheus supports:
Alert rules.
Example alerts:
Lag > 50,000
Disk Usage > 90%
UnderReplicatedPartitions > 0
Broker Offline
Alerts help teams react quickly.
Why Alerting Matters
Without alerts:
- failures may remain unnoticed
Kafka systems often power:
- mission-critical workflows
Immediate detection is essential.
Real-World Example — Payment Systems
Suppose payment pipeline slows down.
Grafana shows:
- lag increasing
- broker CPU rising
- replication slowing
Teams can:
- scale consumers
- add brokers
- optimize partitions
before customer impact becomes severe.
Kafka Monitoring in Kubernetes
Modern Kafka deployments often run on:
Kubernetes
Monitoring also includes:
- pod metrics
- container health
- orchestration visibility
Cloud-native observability becomes important.
Kafka Monitoring and Capacity Planning
Monitoring helps estimate:
- future broker needs
- storage growth
- partition scaling
- consumer throughput requirements
This prevents:
- infrastructure surprises.
Retention Monitoring
Kafka retention affects:
- storage consumption
- replayability
- cleanup behavior
Metrics help teams manage:
- long-term storage growth
effectively.
Troubleshooting Using Dashboards
Suppose:
- consumers slow down
Dashboards may reveal:
- high GC pauses
- overloaded brokers
- disk saturation
- partition imbalance
Observability accelerates troubleshooting dramatically.
Why Visualization Matters
Raw metrics alone are difficult to interpret.
Grafana helps teams:
- understand trends visually
- identify anomalies quickly
- correlate failures
Visualization improves operational decision making.
Common Kafka Monitoring Mistakes
Mistake 1
Monitoring only brokers
Consumers matter equally.
Mistake 2
Ignoring lag growth trends
Lag often predicts outages early.
Mistake 3
No alert thresholds
Monitoring without alerts limits usefulness.
Mistake 4
Ignoring disk usage
Disk exhaustion is one of Kafka’s most dangerous operational risks.
Why Kafka Monitoring Became Essential
Kafka powers:
- real-time systems
- financial platforms
- observability pipelines
- analytics infrastructures
These systems require:
- operational visibility
- proactive monitoring
- rapid incident detection
Prometheus
and
Grafana
became foundational tools for operating Kafka reliably at scale.
Production Monitoring Architecture Example
A common production setup:
Kafka Brokers
↓
JMX Exporter
↓
Prometheus
↓
Grafana
↓
Alertmanager
↓
Slack / Email / PagerDuty
This forms:
- enterprise-grade Kafka observability infrastructure.
Common Beginner Misconceptions
Misconception 1
Kafka monitoring is optional
Production Kafka absolutely requires observability.
Misconception 2
Lag is the only important metric
Replication, disk, JVM, and throughput metrics matter too.
Misconception 3
Grafana stores metrics
Prometheus stores metrics.
Grafana visualizes them.
Misconception 4
Healthy brokers guarantee healthy consumers
Consumer bottlenecks still create failures.
Key Takeaways
Kafka production systems require:
- strong observability
- real-time monitoring
- operational alerting
Prometheus collects:
- Kafka metrics
- broker health data
- consumer statistics
Grafana visualizes:
- dashboards
- lag trends
- throughput
- replication health
Critical Kafka metrics include:
- consumer lag
- throughput
- under-replicated partitions
- disk utilization
- JVM health
Together:
Prometheus
and
Grafana
provide one of the most powerful monitoring stacks for operating:
Apache Kafka
reliably in modern production environments.