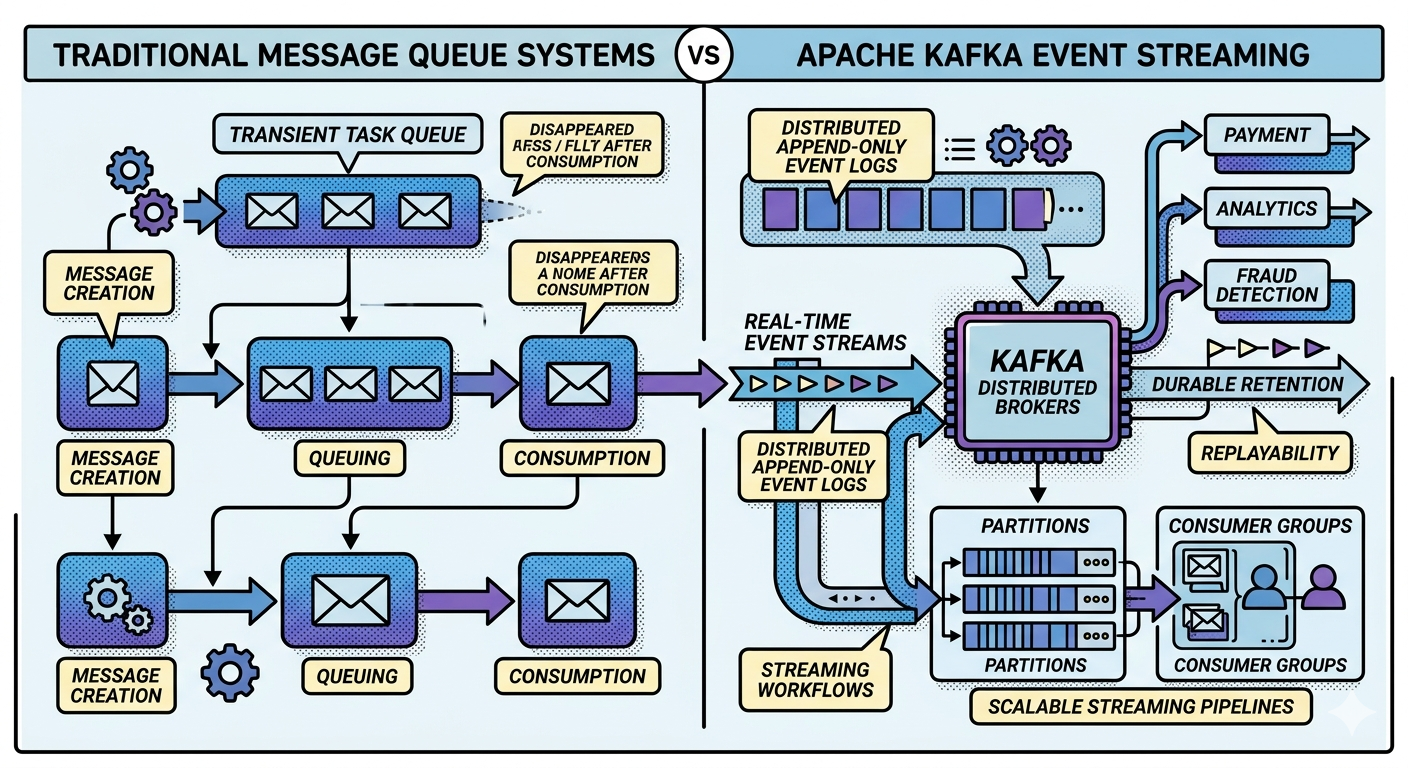
Kafka vs Traditional Message Queues
Understanding What Makes Kafka Fundamentally Different
One of the most common beginner questions about:
Apache Kafka
is:
“Is Kafka just another message queue?”
At first glance, Kafka may appear similar to traditional messaging systems like:
- RabbitMQ
- ActiveMQ
- IBM MQ
- Amazon SQS
All of them:
- send messages
- connect producers and consumers
- support asynchronous communication
But internally, Kafka is fundamentally different.
Kafka was not designed merely as:
- a queue
- a task dispatcher
- a transient messaging broker
Kafka was designed as:
A distributed event streaming platform.
This architectural difference changes:
- scalability
- persistence
- replayability
- throughput
- consumer behavior
- system design philosophy
In this article, we will deeply explore:
- traditional message queues
- Kafka architecture
- queue semantics vs event streaming
- retention and replayability
- consumer behavior
- throughput differences
- scalability models
- real-world architectural tradeoffs
- when to use Kafka vs traditional MQ systems
Understanding these differences is essential for choosing the right architecture.
What is a Traditional Message Queue?
Traditional message queues are designed primarily for:
Reliable message delivery between systems.
Typical workflow:
Producer
↓
Queue
↓
Consumer
Messages are:
- delivered
- processed
- removed
The focus is:
Task distribution and asynchronous processing.
Common Traditional MQ Systems
Popular traditional queue systems include:
- RabbitMQ
- ActiveMQ
- IBM MQ
- Amazon Simple Queue Service
These systems are excellent for:
- work queues
- task processing
- job distribution
- asynchronous APIs
Traditional Queue Philosophy
Traditional MQ systems generally assume:
Message consumed
↓
Message removed
Messages are treated as:
- temporary work items
This works very well for:
- background jobs
- email processing
- image resizing
- task dispatching
Kafka’s Philosophy Is Different
Kafka treats messages as:
Durable event streams.
Instead of:
- deleting immediately after consumption
Kafka:
- retains records persistently
- allows replayability
- enables multiple independent consumers
This is a massive architectural difference.
Queue vs Event Stream
Traditional queue:
Temporary task pipeline
Kafka:
Durable historical event log
This distinction changes everything.
Traditional MQ Example
Suppose e-commerce application sends email task.
Workflow:
OrderPlaced
↓
Email Queue
↓
Email Service
↓
Message Deleted
Once processed:
- task disappears
Simple and efficient.
Kafka Example
Now Kafka workflow:
OrderPlaced Event
↓
Kafka Topic
├── Analytics
├── Fraud Detection
├── Notifications
└── Audit System
Event persists even after consumption.
Multiple systems consume independently.
Why Kafka Retains Events
Kafka retention enables:
- replayability
- analytics rebuilding
- event sourcing
- audit history
- machine learning retraining
Traditional queues are not optimized for these capabilities.
Consumer Behavior Differences
Traditional MQ consumers typically:
- compete for messages
Example:
Queue
├── Worker A
├── Worker B
└── Worker C
One message usually goes to:
- one worker
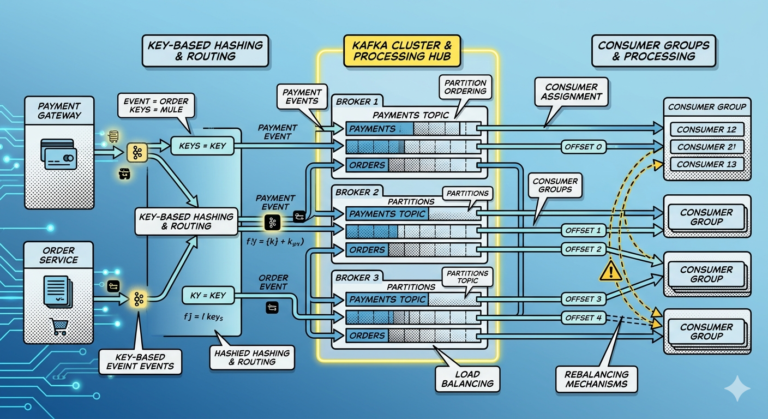
Kafka Consumer Groups
Kafka supports:
- consumer groups
- independent subscriptions
- replayable consumption
Example:
payments topic
├── Fraud Group
├── Analytics Group
├── Audit Group
└── Notification Group
Each group independently consumes events.
This is fundamentally different from traditional queues.
Throughput Differences
Kafka was designed for:
Massive throughput.
Kafka optimizes:
- sequential disk writes
- batching
- append-only logs
- partition parallelism
This enables:
- millions of events per second
Traditional MQ systems usually prioritize:
- flexible routing
- delivery guarantees
- protocol compatibility
rather than extreme streaming throughput.
Why Kafka Scales So Well
Kafka partitions topics:
payments topic
├── Partition 0
├── Partition 1
├── Partition 2
Partitions distribute across:
- brokers
- consumers
This creates:
- horizontal scalability
- distributed parallelism
Traditional MQ Scaling
Traditional queues often scale:
- vertically first
- horizontally with more complexity
Many were originally designed before modern:
- cloud-native
- streaming-scale architectures
Ordering Differences
Traditional MQ systems may support:
- queue-level ordering
Kafka guarantees:
- ordering within partitions only
This allows Kafka to scale massively while preserving local ordering.
Replayability — A Major Difference
Traditional queues typically:
- remove messages after processing
Kafka:
- retains events
- allows replay from historical offsets
Replayability powers:
- analytics rebuilding
- debugging
- recovery
- event sourcing
This is one of Kafka’s most revolutionary features.
Example — Fraud Analytics Replay
Suppose fraud algorithm improves.
Traditional queue:
- historical data unavailable
Kafka:
- replay months of transactions
- rerun fraud detection
Massive advantage for streaming architectures.
Event Streaming vs Task Queues
Traditional MQ:
Focused on task delivery.
Kafka:
Focused on continuous event streams.
This distinction matters enormously.
Traditional MQ Strengths
Traditional queues excel at:
- task dispatching
- request buffering
- asynchronous jobs
- RPC decoupling
- complex routing patterns
Especially for:
- smaller workloads
- transactional workflows
- enterprise integration
Kafka Strengths
Kafka excels at:
- event streaming
- real-time analytics
- event sourcing
- distributed logs
- massive throughput
- scalable Pub/Sub systems
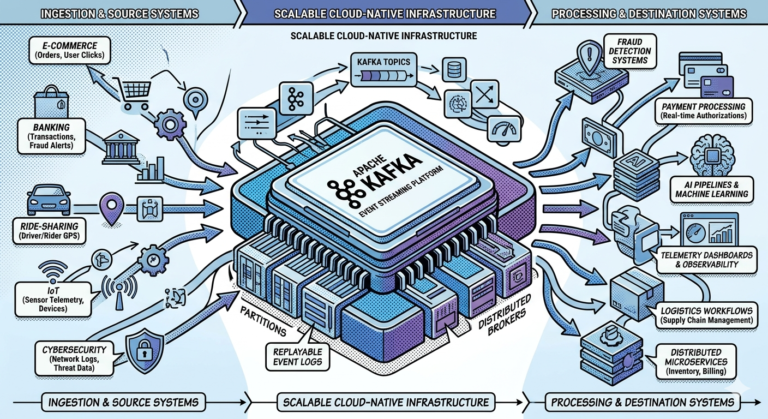
Real-Time Streaming Architectures
Kafka became dominant because modern systems increasingly require:
- continuous event flows
- streaming analytics
- real-time pipelines
- distributed event backbones
Traditional MQ systems were not originally optimized for this scale.
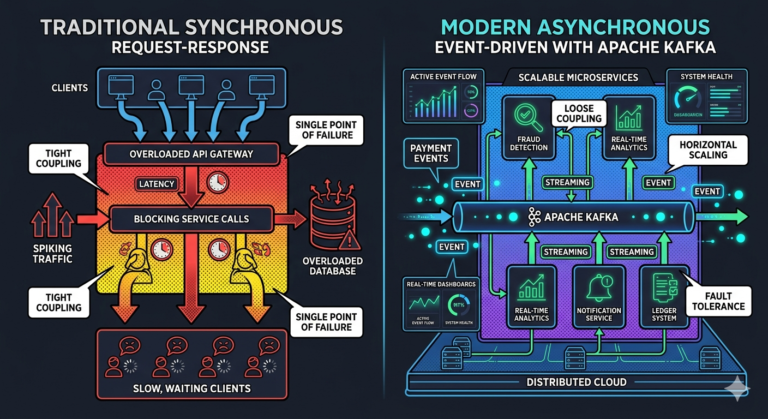
Pull vs Push Consumption
Traditional MQ systems often use:
Push-based delivery.
Broker pushes messages to consumers.
Kafka uses:
Pull-based consumption.
Consumers poll Kafka themselves.
Why Pull-Based Consumption Matters
Kafka consumers control:
- reading speed
- batching
- backpressure handling
This improves:
- scalability
- stability
- throughput management
Durability Differences
Kafka stores events durably:
- sequentially on disk
- replicated across brokers
Traditional MQ durability models vary significantly depending on:
- configuration
- broker type
- persistence settings
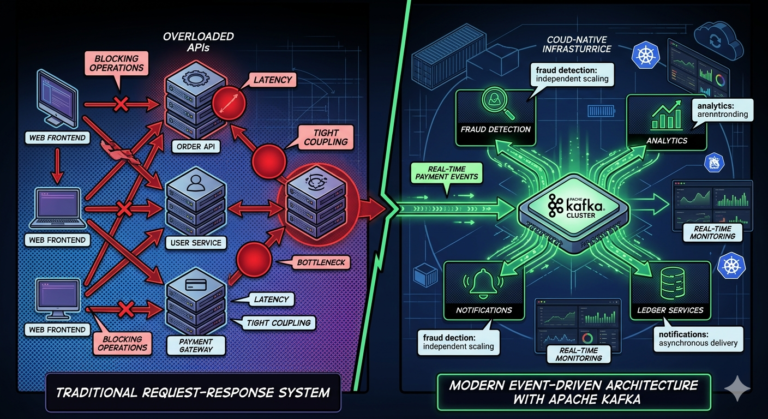
Kafka as Infrastructure Backbone
Many organizations use Kafka as:
Central nervous system for enterprise events.
Examples:
- payment systems
- observability pipelines
- banking workflows
- streaming analytics
- IoT infrastructures
Traditional MQ systems usually occupy narrower messaging roles.
Real-World Example — Ride Sharing
Ride-sharing platform may stream:
- ride requests
- driver locations
- pricing updates
- payment events
continuously through Kafka.
This is streaming infrastructure, not merely queue processing.
Real-World Example — Background Email Jobs
Suppose application needs:
- email sending
- thumbnail generation
- PDF creation
Traditional MQ may be simpler and more appropriate.
Kafka would often be unnecessary overhead.
Kafka Is Not Always the Right Choice
Kafka introduces:
- operational complexity
- partition management
- retention planning
- streaming architecture concerns
For simple queues:
- RabbitMQ or SQS may be easier.
Architecture should match requirements.
When to Use Traditional MQ
Traditional MQ systems are excellent for:
- task queues
- background jobs
- request buffering
- command processing
- lightweight asynchronous workflows
When to Use Kafka
Kafka excels for:
- event-driven architectures
- streaming systems
- real-time analytics
- large-scale distributed processing
- replayable event history
- CQRS and event sourcing
Why Kafka Changed Industry Architecture
Kafka shifted industry thinking from:
Temporary messaging
to:
Persistent event streams
This fundamentally transformed modern distributed systems.
Common Beginner Misconceptions
Misconception 1
Kafka is just a faster RabbitMQ
Kafka and traditional MQ systems solve different architectural problems.
Misconception 2
Traditional queues cannot scale
They scale well for many messaging workloads.
Misconception 3
Kafka replaces all message brokers
Kafka complements rather than universally replaces MQ systems.
Misconception 4
Replayability exists naturally in all messaging systems
Kafka’s retention model is fundamentally different.
Why Understanding This Difference Matters
Architectural decisions depend heavily on understanding:
- queue semantics
- streaming semantics
- retention models
- throughput needs
- replayability requirements
Choosing incorrectly can create:
- unnecessary complexity
- scalability bottlenecks
- operational pain
Key Takeaways
Traditional message queues focus on:
- temporary task delivery
- asynchronous processing
- message removal after consumption
Kafka focuses on:
- durable event streams
- replayability
- distributed scalability
- real-time streaming
Kafka topics behave like:
- append-only distributed logs
while traditional queues behave more like:
- transient work pipelines
Kafka excels for:
- event-driven architectures
- analytics pipelines
- stream processing
- replayable event history
Traditional MQ systems excel for:
- background jobs
- task queues
- lightweight asynchronous messaging
Understanding these architectural differences is essential when designing scalable distributed systems using:
Apache Kafka