Zookeeper vs KRaft — Why Kafka Architecture Changed
Understanding Kafka’s Evolution from External Coordination to Built-In Metadata Management
For many years, one of the most common statements associated with:
Apache Kafka
was:
“Kafka depends on Zookeeper.”
Anyone installing Kafka traditionally needed:
- Kafka brokers
- Apache Zookeeper
- broker registration
- cluster coordination setup
But modern Kafka deployments are changing dramatically.
Kafka is moving away from Zookeeper and toward:
KRaft mode.
This architectural shift represents one of the biggest changes in Kafka’s history.
In this article, we will deeply explore:
- why Kafka originally used Zookeeper
- what Zookeeper actually did
- the operational problems it created
- what KRaft is
- how KRaft works
- architectural differences
- benefits of KRaft
- why Kafka evolved toward self-managed metadata
Understanding this transition is extremely important for anyone learning modern Kafka architecture.
Why Distributed Systems Need Coordination
Kafka is a distributed system.
Distributed systems must coordinate:
- broker membership
- partition leadership
- metadata updates
- replica synchronization
- controller election
- cluster state
Without coordination:
- brokers would disagree
- partition leadership could conflict
- data consistency would break
Kafka needed a reliable coordination mechanism.
Enter Apache Zookeeper
Historically, Kafka relied on:
Apache ZooKeeper
for distributed coordination.
Zookeeper acted as:
Kafka’s centralized metadata and coordination system.
What is Zookeeper?
Zookeeper is a distributed coordination service designed to manage:
- configuration
- naming
- synchronization
- distributed consensus
- leader election
Many distributed systems historically used Zookeeper.
Kafka was one of the most famous examples.
Why Kafka Initially Needed Zookeeper
Early Kafka versions were designed primarily for:
- distributed log storage
- partition replication
- event streaming
But Kafka lacked:
- internal metadata consensus
- cluster coordination mechanisms
Zookeeper solved these problems externally.
What Zookeeper Managed in Kafka
Zookeeper handled several critical responsibilities.
1. Broker Registration
When Kafka brokers started:
Broker 1 starts
Broker 2 starts
Broker 3 starts
Each broker registered itself with Zookeeper.
Zookeeper maintained:
- broker IDs
- cluster membership
- broker availability
2. Controller Election
Kafka clusters require:
One controller broker.
The controller manages:
- partition leadership
- failover coordination
- metadata updates
Zookeeper handled controller election.
3. Partition Leader Election
Suppose:
Partition 0 leader broker fails
Kafka needed a new leader.
Zookeeper coordinated:
- leader reassignment
- replica promotion
- metadata propagation
4. Metadata Storage
Kafka cluster metadata includes:
- topics
- partitions
- replicas
- broker information
- ACLs
- configurations
Historically:
- Zookeeper stored this metadata centrally.
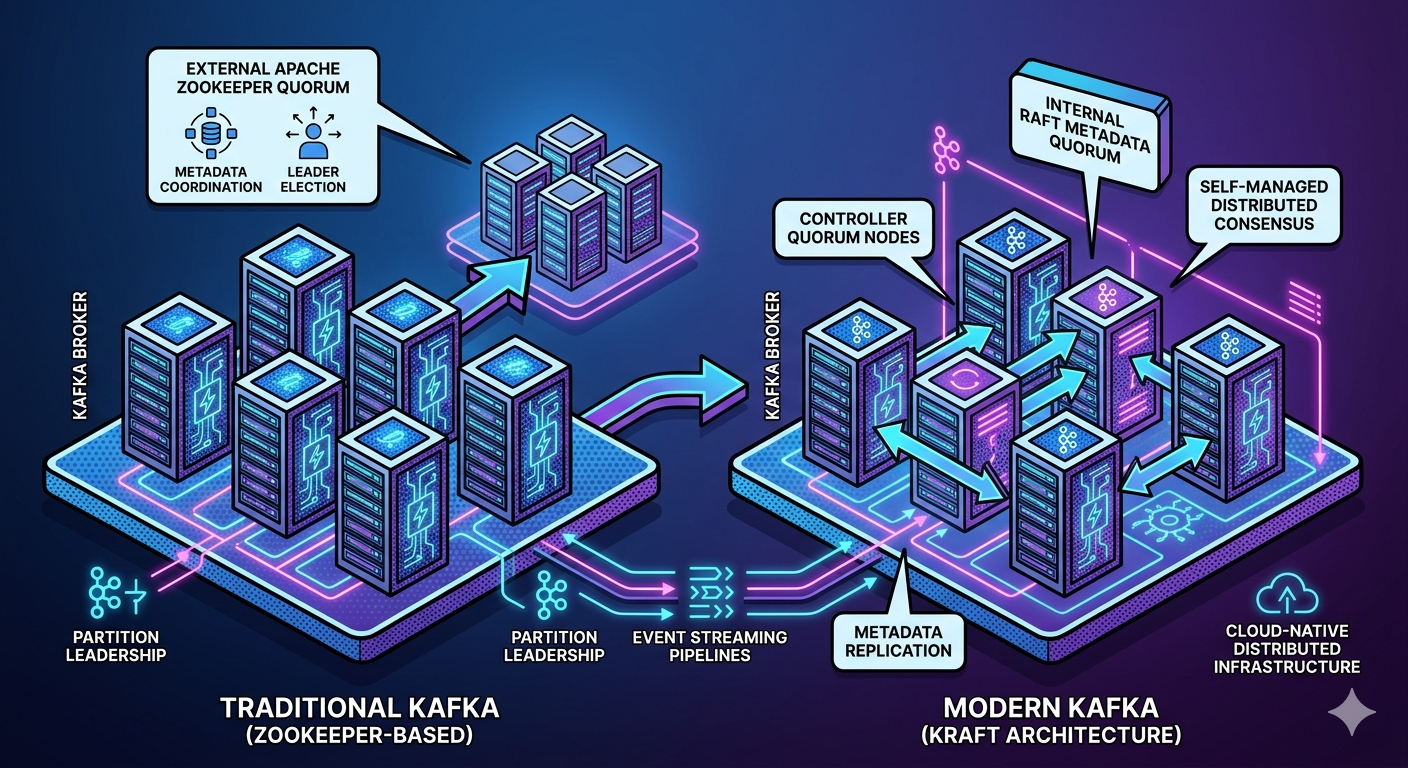
Traditional Kafka Architecture
Classic Kafka architecture looked like this:
Producers
↓
Kafka Brokers
↓
Zookeeper
Kafka depended heavily on Zookeeper coordination.
Why This Became a Problem
As Kafka adoption exploded:
- cluster sizes increased
- partition counts exploded
- metadata operations scaled massively
Operational complexity became painful.
Major Problems with Zookeeper-Based Kafka
1. Operational Complexity
Kafka deployments required managing:
- Kafka cluster
- Zookeeper ensemble
This doubled infrastructure complexity.
Teams now had to:
- monitor two distributed systems
- configure two systems
- secure two systems
- troubleshoot two systems
2. Scalability Limitations
Large Kafka clusters generated enormous metadata activity.
Example:
- broker joins
- partition reassignments
- topic creation
- leader elections
Zookeeper struggled at very large scale.
3. Metadata Bottlenecks
Metadata updates became increasingly expensive.
Large clusters with:
- thousands of brokers
- hundreds of thousands of partitions
created operational stress.
4. Complex Failure Recovery
Zookeeper failures could impact:
- cluster coordination
- controller elections
- metadata consistency
Troubleshooting distributed coordination became difficult.
5. Difficult Operational Learning Curve
New Kafka engineers had to understand:
- Kafka internals
- Zookeeper internals
- quorum configuration
- ensemble tuning
This increased adoption friction.
Kafka Needed Architectural Simplification
As Kafka matured, the community recognized:
Kafka should manage its own metadata internally.
Instead of relying on external coordination.
This led to:
KRaft.
What is KRaft?
KRaft stands for:
Kafka Raft Metadata Mode.
KRaft removes Zookeeper completely.
Kafka now manages:
- metadata
- controller quorum
- distributed consensus
internally.
Modern Kafka Architecture
With KRaft:
Producers
↓
Kafka Brokers
↓
Internal Metadata Quorum
No external Zookeeper dependency.
What Changed in KRaft?
Kafka introduced:
An internal Raft-based consensus system.
Kafka brokers themselves now handle:
- metadata replication
- leader election
- controller coordination
What is Raft?
Raft is a distributed consensus algorithm.
It helps distributed systems agree on:
- cluster state
- metadata consistency
- leadership decisions
Raft is widely respected for being:
- understandable
- reliable
- fault tolerant
Kafka’s Metadata Quorum
In KRaft mode:
- selected Kafka nodes form a metadata quorum
These nodes maintain:
- cluster metadata
- controller state
- partition assignments
- broker membership
internally.
KRaft Controller Nodes
KRaft introduces:
Controller quorum nodes.
These nodes manage:
- metadata replication
- cluster coordination
- controller leadership
similar to what Zookeeper previously handled.
Example KRaft Architecture
Kafka Cluster
├── Broker 1
├── Broker 2
├── Broker 3
├── Controller 1
├── Controller 2
└── Controller 3
In smaller clusters:
- brokers and controllers may coexist on same nodes.
Why KRaft is Better
KRaft provides several major improvements.
1. Simpler Architecture
No separate Zookeeper cluster.
This reduces:
- infrastructure overhead
- operational complexity
- deployment friction
2. Better Scalability
Kafka metadata handling becomes more efficient.
KRaft supports:
- larger clusters
- more partitions
- improved metadata throughput
3. Faster Recovery
Leader election and metadata synchronization improve significantly.
This reduces:
- failover delays
- controller instability
4. Unified Security Model
Previously:
- Kafka security
- Zookeeper security
required separate management.
KRaft simplifies this considerably.
5. Easier Operations
Teams manage:
- one distributed platform instead of two
This simplifies:
- upgrades
- monitoring
- debugging
- automation
Why This Transition Took Time
Removing Zookeeper was not easy.
Kafka had to redesign:
- metadata architecture
- controller logic
- replication coordination
- distributed consensus
This required years of engineering work.
Kafka Metadata Log
In KRaft mode:
- metadata itself is stored in Kafka logs
This is an important architectural shift.
Kafka now treats metadata similarly to event streams:
- replicated
- ordered
- durable
Metadata as an Event Stream
This is conceptually elegant.
Metadata changes become ordered records like:
TopicCreated
PartitionAssigned
BrokerRegistered
LeaderElected
Kafka internally processes these changes consistently.
KRaft and Controller Quorum
KRaft controllers form:
A quorum.
Example:
Controller 1
Controller 2
Controller 3
Consensus ensures:
- consistent metadata state
- fault tolerance
- safe failover
What Happens if a Controller Fails?
Suppose:
Controller 1 crashes
Remaining quorum members continue functioning.
A new leader is elected safely.
This maintains cluster stability.
KRaft Improves Startup Times
Traditional Kafka clusters often experienced:
- slower broker startup
- metadata synchronization delays
KRaft improves:
- initialization speed
- metadata propagation efficiency
Is Zookeeper Completely Gone?
Modern Kafka strongly encourages:
KRaft mode.
However:
- some legacy deployments still use Zookeeper
- migration is ongoing in enterprises
But the future of Kafka is clearly:
KRaft-native architecture.
Migration Considerations
Organizations migrating from Zookeeper to KRaft must consider:
- metadata migration
- cluster downtime planning
- version compatibility
- operational testing
Migration strategies vary depending on cluster size.
Why This Architectural Evolution Matters
KRaft represents Kafka’s evolution from:
- messaging platform
to:
- fully self-managed distributed streaming infrastructure.
This significantly strengthens Kafka’s position as:
- enterprise event backbone
- distributed streaming platform
- cloud-native infrastructure technology
Real-World Impact
KRaft benefits organizations running:
- massive Kafka clusters
- high partition counts
- cloud-native streaming systems
- enterprise event platforms
The simplification is especially valuable at scale.
Common Beginner Misconceptions
Misconception 1
Kafka and Zookeeper are the same thing
They were separate systems.
Misconception 2
Zookeeper stored Kafka event data
Kafka brokers stored event data.
Zookeeper stored metadata.
Misconception 3
KRaft removes distributed coordination
KRaft internalizes coordination.
Misconception 4
KRaft is optional future technology
KRaft is now the strategic direction of Kafka.
Why KRaft is a Major Milestone
KRaft transformed Kafka into:
- a self-contained distributed platform
- a simpler operational system
- a more scalable metadata architecture
This architectural modernization is one reason:
Apache Kafka
continues dominating modern event streaming infrastructure.
Key Takeaways
Historically, Kafka relied on:
Apache ZooKeeper
for:
- metadata storage
- broker coordination
- controller election
- partition leadership
As Kafka scaled, Zookeeper introduced:
- operational complexity
- scalability bottlenecks
- infrastructure overhead
KRaft replaces Zookeeper by introducing:
- internal Raft-based metadata management
- controller quorum nodes
- distributed consensus inside Kafka itself
This makes modern Kafka:
- simpler
- more scalable
- easier to operate
- better suited for large-scale event streaming systems