Introduction to CQRS Using Kafka
Separating Reads and Writes for Scalable Event-Driven Systems
As modern applications scale, traditional architectures often begin struggling with:
- database bottlenecks
- heavy read traffic
- complex transactional workloads
- slow reporting systems
- tightly coupled services
A single database handling:
- writes
- reads
- analytics
- search queries
- reporting
- caching
can quickly become overwhelmed.
To solve this, many distributed systems adopt:
CQRS — Command Query Responsibility Segregation.
When combined with:
Apache Kafka
CQRS becomes an extremely powerful architectural pattern for building:
- scalable systems
- real-time applications
- event-driven workflows
- distributed microservices
- streaming platforms
In this article, we will deeply explore:
- what CQRS is
- why CQRS exists
- commands vs queries
- read/write separation
- Kafka-driven CQRS architectures
- event propagation
- projections
- eventual consistency
- real-world use cases
- architectural tradeoffs
CQRS is one of the most important architectural patterns in modern event-driven systems.
What is CQRS?
CQRS stands for:
Command Query Responsibility Segregation.
The core idea is simple:
Separate write operations from read operations.
Instead of using:
- one model
- one database
- one service layer
for everything,
CQRS separates:
- commands (writes)
- queries (reads)
into independent models.
Understanding Commands and Queries
Commands
Commands:
- change system state
- modify data
- trigger workflows
Examples:
PlaceOrder
ProcessPayment
CreateShipment
CancelBooking
Commands represent:
Intent to change something.
Queries
Queries:
- retrieve information
- do not modify state
Examples:
GetCustomerOrders
ViewTransactionHistory
FetchFraudReport
GetAnalyticsDashboard
Queries represent:
Requests for information.
Traditional Architecture Problem
Most traditional applications use:
Single Database
↓
Handles Reads + Writes
Example:
E-commerce Database
├── Order Creation
├── Inventory Updates
├── Customer Queries
├── Reporting
└── Analytics
Everything hits:
- same tables
- same indexes
- same infrastructure
This creates scaling challenges.
Problems with Traditional Read/Write Models
As systems grow:
- read traffic explodes
- writes become contention-heavy
- reporting slows transactions
- indexing becomes complicated
Especially in:
- payment systems
- banking platforms
- e-commerce
- analytics-heavy systems
Why Reads and Writes Behave Differently
Read workloads often require:
- denormalized data
- optimized indexes
- caching
- aggregation
Write workloads require:
- transactional consistency
- validation
- integrity checks
Trying to optimize both together becomes difficult.
CQRS Solves This Separation Problem
CQRS separates:
Write Side
and
Read Side
into independent systems.
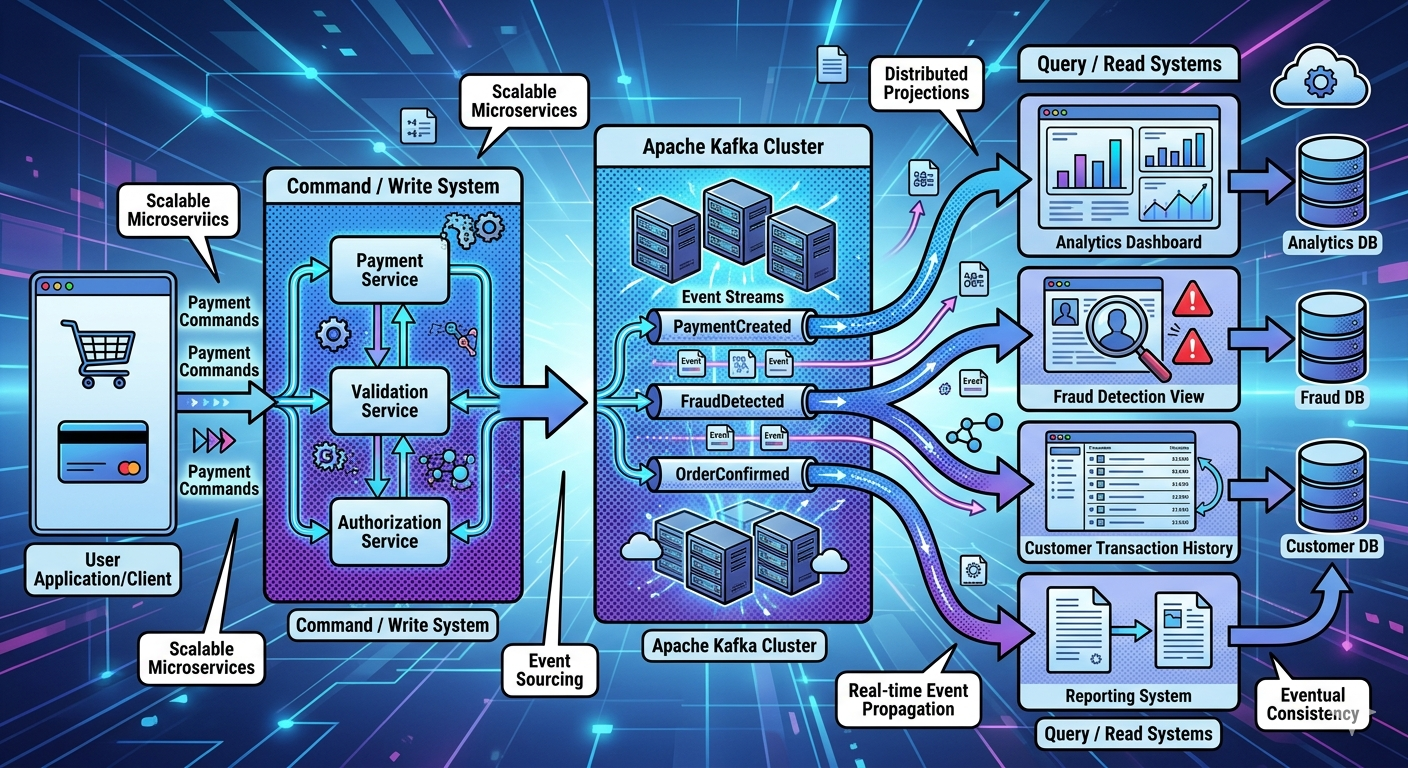
High-Level CQRS Architecture
Commands
↓
Write Model
↓
Events
↓
Read Models / Projections
↓
Queries
Kafka often becomes:
The event backbone connecting these components.
Understanding the Write Side
The write side handles:
- commands
- business rules
- validations
- transactional updates
Example:
PlaceOrder Command
The system:
- validates inventory
- checks payment
- creates order
Then publishes:
OrderPlaced Event
into Kafka.
Understanding the Read Side
The read side focuses on:
- fast queries
- optimized retrieval
- denormalized views
- reporting
Read models subscribe to Kafka events and build:
Projections.
What is a Projection?
A projection is:
A query-optimized view of data.
Example:
Customer Order History View
built from:
- OrderPlaced
- PaymentCompleted
- ShipmentCreated
events.
Why Projections Matter
Instead of:
- expensive joins
- complex transactional queries
CQRS creates:
- precomputed read models
This dramatically improves:
- query performance
- scalability
- responsiveness
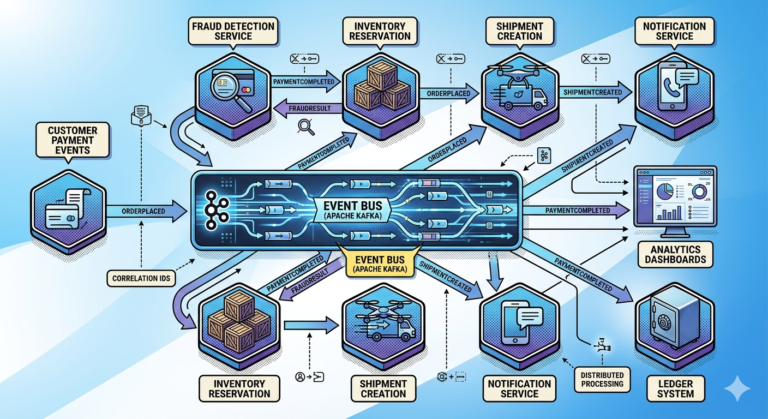
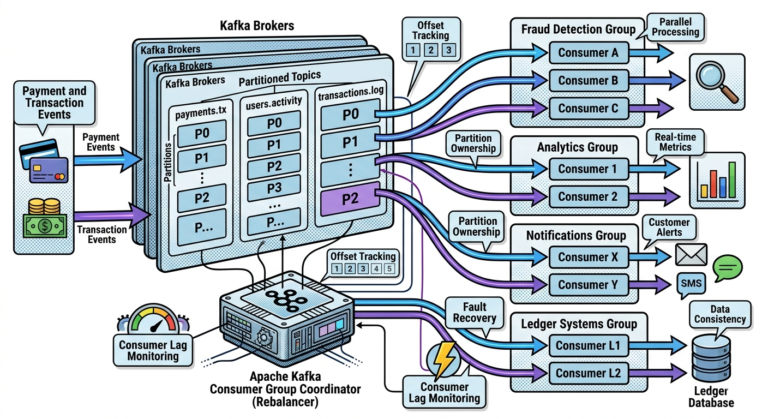
Kafka’s Role in CQRS
Apache Kafka
acts as:
The event distribution backbone.
Workflow:
Command Processed
↓
Event Published to Kafka
↓
Read Models Subscribe
↓
Projections Updated
This creates loosely coupled architecture.
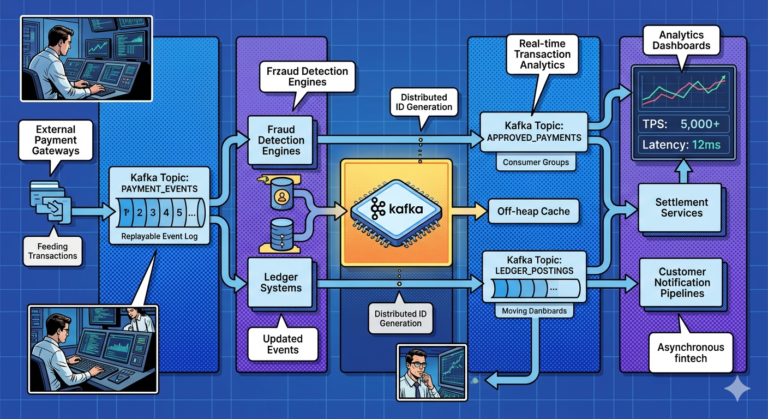
Real-World Payment Example
Suppose customer completes payment.
Step 1 — Command Received
ProcessPayment
Step 2 — Write Model Executes
Payment service:
- validates transaction
- updates ledger
- commits write transaction
Step 3 — Event Published
Kafka receives:
PaymentCompleted
Step 4 — Read Models Update
Multiple projections consume event:
Customer Transaction History
Fraud Dashboard
Accounting Reports
Analytics Metrics
Each independently updated.
Why This Architecture Scales So Well
Read traffic often exceeds write traffic massively.
Example:
- 1 payment write
- thousands of customer queries
- dashboard reads
- reporting requests
CQRS allows:
- independent scaling of read systems
without affecting writes.
Independent Read Databases
CQRS often uses specialized databases for reads.
Examples:
| Use Case | Read Database |
|---|---|
| Search | Elasticsearch |
| Analytics | ClickHouse |
| Caching | Redis |
| Reporting | PostgreSQL replicas |
Kafka streams events into these systems.
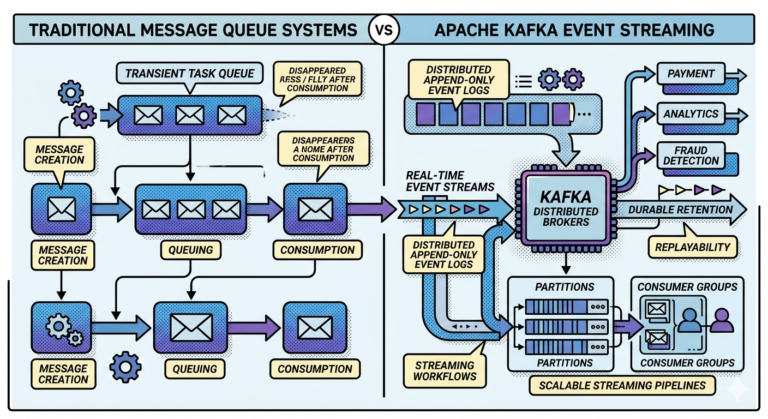
Why Kafka Is Ideal for CQRS
Kafka naturally supports CQRS because it provides:
- durable event streams
- replayability
- asynchronous propagation
- distributed scalability
Kafka topics become:
The synchronization mechanism between writes and reads.
Eventual Consistency in CQRS
CQRS systems are usually:
Eventually consistent.
Meaning:
- write succeeds first
- read models update asynchronously
There may be small delay between:
- command completion
and: - query visibility
Example of Eventual Consistency
Customer places order.
Immediately afterward:
Order History Query
may temporarily not show new order.
A few milliseconds later:
- projection updates
- query becomes consistent
This is normal in distributed systems.
Why Eventual Consistency Is Acceptable
Most large-scale systems prioritize:
- scalability
- availability
- responsiveness
over:
- immediate global consistency
This tradeoff enables:
- high throughput
- distributed scaling
CQRS and Event Sourcing
CQRS is often paired with:
Event Sourcing.
Instead of storing only current state:
- systems store all events
Example:
OrderPlaced
PaymentCompleted
ShipmentCreated
State reconstructed from event history.
Kafka fits naturally into this model.
Real-World Example — Banking
Banking systems often use CQRS for:
- transaction processing
- fraud analytics
- customer dashboards
- reporting systems
Write systems focus on:
- transactional correctness
Read systems optimize:
- customer visibility
- analytics
- auditing
Real-World Example — E-Commerce
E-commerce platforms separate:
- order processing
- inventory writes
from:
- search
- recommendations
- reporting
- customer views
Kafka distributes updates across all systems.
Real-Time Analytics with CQRS
Kafka enables:
- streaming analytics projections
Dashboards update continuously from event streams.
This is extremely common in:
- fintech
- observability
- cybersecurity
- logistics
CQRS Improves Microservices Decoupling
Without CQRS:
All services depend on shared database
With CQRS:
Services communicate through events
This enables:
- independent deployments
- service isolation
- scalability
Challenges of CQRS
CQRS introduces additional complexity.
1. Eventual Consistency
Read models lag behind writes.
Applications must tolerate temporary inconsistency.
2. More Infrastructure
CQRS often requires:
- multiple databases
- event streaming infrastructure
- projection services
3. Debugging Complexity
Tracing:
- commands
- events
- projections
becomes more complicated.
4. Data Duplication
Read models intentionally duplicate data for query optimization.
This is acceptable in CQRS systems.
When CQRS Is Worth It
CQRS is valuable when systems have:
- massive read traffic
- complex reporting
- real-time analytics
- distributed workflows
- scalability requirements
Small CRUD applications usually do not need CQRS.
Common Beginner Misconceptions
Misconception 1
CQRS requires multiple databases
Not always.
Logical separation matters more initially.
Misconception 2
CQRS eliminates consistency problems
CQRS embraces eventual consistency.
Misconception 3
CQRS is only about performance
CQRS also improves:
- scalability
- decoupling
- architecture flexibility
Misconception 4
Kafka automatically implements CQRS
Kafka enables CQRS patterns.
Application design still matters.
Why CQRS Became So Popular
Modern systems increasingly require:
- scalable reads
- distributed workflows
- asynchronous architectures
- event-driven processing
CQRS solves these challenges elegantly when combined with:
Apache Kafka
and event-driven design.
Key Takeaways
CQRS separates:
- commands (writes)
from: - queries (reads)
This enables:
- independent scaling
- optimized read models
- distributed event-driven workflows
Kafka acts as:
- the event propagation backbone
connecting:
- write systems
- read projections
- analytics pipelines
- query models
CQRS systems typically embrace:
- asynchronous processing
- eventual consistency
- event-driven synchronization
This architecture is widely used in:
- fintech
- e-commerce
- analytics platforms
- real-time distributed systems
to achieve scalable and resilient event-driven architectures.