What is Apache Kafka and Why is it So Popular?
Understanding the Distributed Event Streaming Platform Powering Modern Systems
Over the last decade, one technology has become almost synonymous with large-scale event-driven systems:
Apache Kafka
From:
- payment processing systems,
- banking platforms,
- ride-sharing applications,
- e-commerce systems,
- streaming analytics,
- cybersecurity platforms,
- IoT infrastructures,
to real-time observability pipelines, Kafka has become the backbone of modern distributed architectures.
But what exactly is Kafka?
Why did enterprises adopt it so aggressively?
What makes it different from traditional messaging systems?
And why is it considered foundational for Event-Driven Architecture (EDA)?
In this article, we will explore:
- what Kafka is
- the problem Kafka solves
- Kafka’s origin story
- distributed log architecture
- high-throughput design
- durability and fault tolerance
- event streaming concepts
- why Kafka became the industry standard
This article marks the transition from general EDA concepts into Kafka-specific architecture.
The Problem Modern Systems Faced
As companies scaled their systems, they encountered major challenges:
- massive volumes of real-time data
- growing microservices ecosystems
- distributed architectures
- scalability bottlenecks
- unreliable integrations
- overloaded databases
- slow analytics pipelines
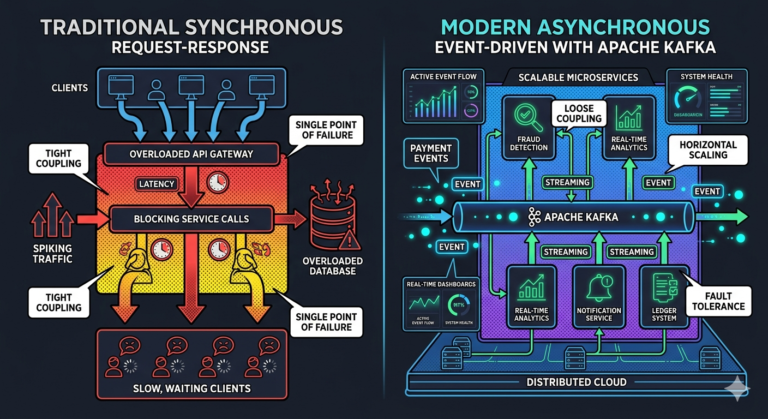
Traditional architectures struggled to process data fast enough.
Example — E-Commerce Explosion
Imagine a modern e-commerce platform.
Every customer action generates events:
ProductViewed
CartUpdated
OrderPlaced
PaymentCompleted
ShipmentCreated
Millions of such events may occur every minute.
These events must be consumed by:
- recommendation engines
- fraud systems
- analytics platforms
- notification systems
- inventory services
Traditional request-response systems become overwhelmed quickly.
Kafka Was Created to Solve This Problem
Apache Kafka was originally developed at LinkedIn.
LinkedIn needed a platform capable of:
- handling massive event streams
- processing activity data in real time
- scaling horizontally
- supporting fault tolerance
- decoupling services
Kafka was later open-sourced and became one of the most widely adopted distributed systems technologies in the world.
What is Apache Kafka?
Kafka is a:
Distributed event streaming platform.
It allows systems to:
- publish events
- store events
- process events
- stream events
- replay events
- scale event pipelines horizontally
Kafka combines the capabilities of:
- messaging systems
- distributed logs
- stream processing platforms
- event storage systems
into a single architecture.
Kafka in Simple Terms
At a high level:
Producer → Kafka → Consumer
Producers publish events.
Kafka stores and distributes them.
Consumers process them independently.
Simple concept.
Massive scalability.
Why Kafka is Different from Traditional Messaging Systems
Traditional messaging systems usually focus on:
- temporary delivery
- message queues
- short-lived processing
Kafka introduced a fundamentally different model:
Persistent distributed event logs.
This changed everything.
Kafka is Built Around a Distributed Log
This is one of the most important concepts in Kafka.
Kafka stores events inside an append-only log.
Events are:
- written sequentially
- never modified
- ordered within partitions
Visualizing the Log
Imagine a continuously growing journal:
Offset 0 → OrderPlaced
Offset 1 → PaymentCompleted
Offset 2 → InventoryReserved
Offset 3 → ShipmentCreated
New events are appended continuously.
Kafka consumers read from this log independently.
Why the Distributed Log Model is Powerful
The distributed log architecture enables:
- replayability
- scalability
- durability
- fault tolerance
- consumer independence
This is one of Kafka’s biggest innovations.
Kafka Stores Events Durably
Unlike many traditional queues:
Kafka retains events even after consumption.
This means:
- consumers can replay history
- systems can recover easily
- analytics can process historical data
- new services can consume old events
Kafka becomes both:
- a messaging platform
- a long-term event storage system
Kafka Enables Event Replay
Suppose an analytics service crashes.
With Kafka:
- restart consumer
- continue from previous offset
- replay historical events if necessary
This is incredibly valuable in distributed systems.
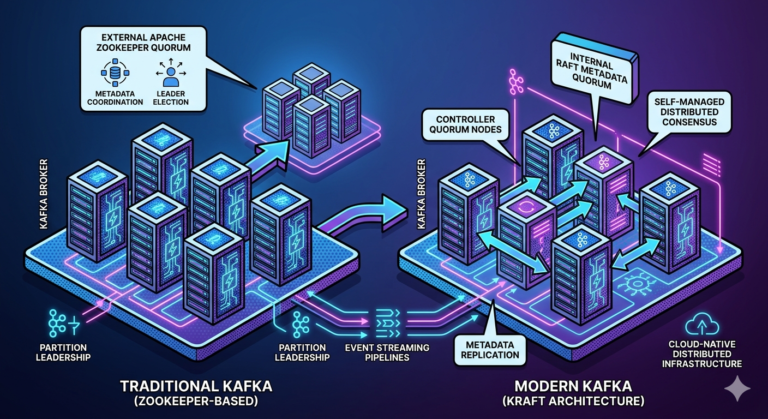
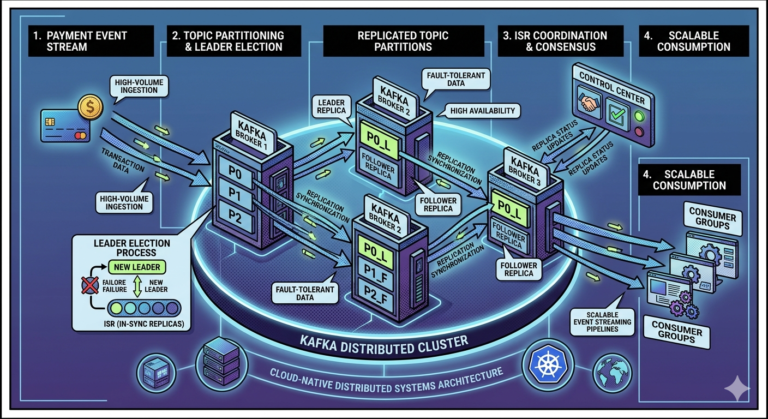
Kafka is Distributed by Design
Kafka is not a single server.
It is designed as a distributed cluster.
Example:
Broker 1
Broker 2
Broker 3
Events are distributed across brokers for:
- scalability
- redundancy
- fault tolerance
What is a Kafka Broker?
A broker is a Kafka server responsible for:
- storing data
- serving consumers
- receiving producer events
- managing partitions
A Kafka cluster typically contains multiple brokers.
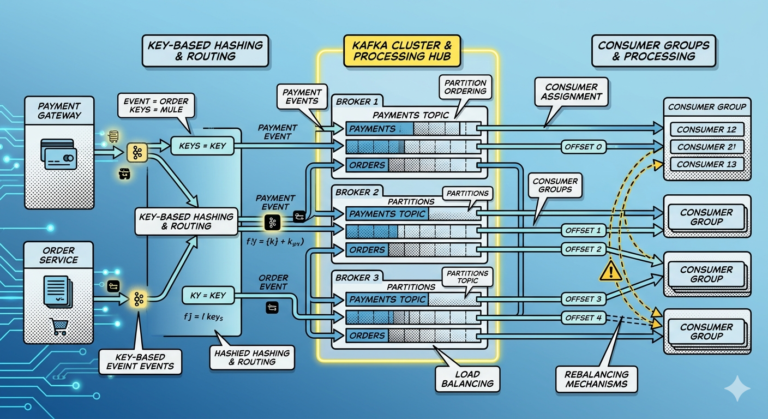
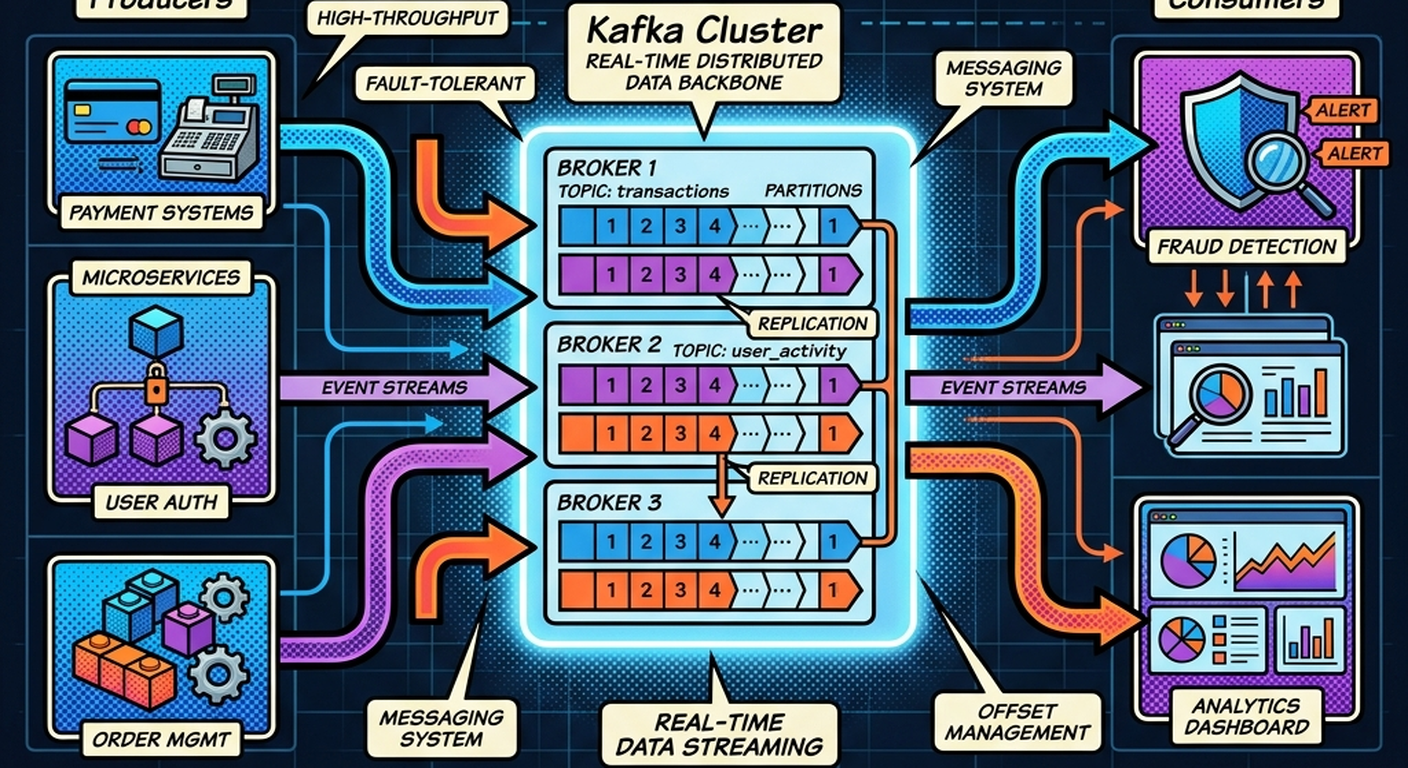
Topics — Kafka’s Event Categories
Kafka organizes events into:
Topics.
Examples:
payments
orders
notifications
fraud-alerts
Topics group related event streams together.
Kafka Partitions — The Secret Behind Scalability
Topics are divided into:
Partitions.
Partitions enable:
- parallel processing
- horizontal scalability
- high throughput
Example:
payments topic
├── Partition 0
├── Partition 1
├── Partition 2
Different consumers can process partitions independently.
This allows Kafka to scale massively.
We will explore partitions deeply in upcoming articles.
Kafka Handles Massive Throughput
Kafka is optimized for:
- sequential disk writes
- batching
- compression
- distributed processing
This allows Kafka to process:
- millions of events per second
- with low latency
Very few systems achieve this efficiently.
Why Sequential Writes Matter
Traditional databases often perform:
- random writes
- transactional updates
Kafka appends data sequentially.
Sequential writes are extremely fast on modern disks and SSDs.
This is a major reason for Kafka’s performance.
Kafka Enables Loose Coupling
Without Kafka:
Payment Service → Fraud Service
Payment Service → Analytics Service
Payment Service → Notification Service
Tight coupling.
With Kafka:
Payment Service → Kafka
Consumers subscribe independently.
This enables:
- independent deployments
- easier scaling
- isolated failures
Kafka Supports Fault Tolerance
Kafka replicates partitions across brokers.
Example:
Partition replicated across:
Broker 1
Broker 2
Broker 3
If one broker fails:
- another replica becomes leader
- processing continues
This provides high availability.
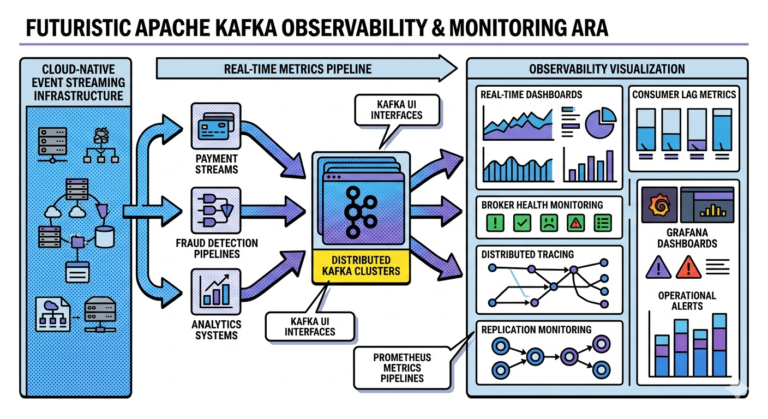
Kafka Enables Real-Time Systems
Modern applications require:
- real-time dashboards
- instant fraud detection
- live notifications
- streaming analytics
- continuous monitoring
Kafka makes these architectures practical.
Kafka and Event-Driven Architecture
Kafka became central to EDA because it naturally supports:
- asynchronous communication
- event streams
- independent consumers
- replayability
- distributed processing
Kafka acts as the “central nervous system” connecting distributed systems.
Real-World Kafka Use Cases
1. Payment Processing Systems
Events:
PaymentCompleted
RefundIssued
FraudDetected
Kafka distributes them across multiple systems.
2. Fraud Detection Pipelines
Real-time transaction streams are analyzed continuously.
Kafka enables:
- high throughput
- low latency
- streaming analytics
3. Ride-Sharing Platforms
Continuous streams:
- driver locations
- ride requests
- payments
- surge pricing
Kafka handles massive event velocity.
4. Observability Systems
Logs, metrics, and traces can all stream through Kafka.
Modern observability platforms often rely heavily on Kafka pipelines.
Kafka vs Traditional Queues
Many beginners think Kafka is “just another message queue.”
Not exactly.
Traditional Queue Model
Producer → Queue → Consumer
Message removed after consumption.
Kafka Model
Producer → Distributed Log → Multiple Independent Consumers
Events persist.
Consumers track their own progress independently.
This is a fundamentally different architecture.
Kafka Consumers Track Offsets
Kafka consumers maintain:
Offsets.
An offset represents:
- the current reading position inside a partition
Example:
Consumer currently at Offset 1050
This enables:
- replayability
- independent consumption
- fault recovery
We will explore offsets deeply in upcoming articles.
Kafka Became Popular Because It Solved Multiple Problems Together
Kafka unified:
- messaging
- streaming
- storage
- distributed processing
- replay capability
Most older systems solved only parts of these problems.
Kafka solved them together at scale.
Why Enterprises Love Kafka
Large organizations value Kafka because it enables:
- scalable architectures
- resilient systems
- asynchronous workflows
- real-time processing
- platform standardization
Kafka often becomes enterprise infrastructure.
Kafka and Microservices
Microservices architectures heavily benefit from Kafka.
Why?
Because Kafka:
- decouples services
- supports asynchronous workflows
- enables event choreography
- improves resilience
Kafka integrates naturally with distributed microservices ecosystems.
Common Beginner Misconception
Many people initially think:
Kafka = Queue
But Kafka is much more accurately described as:
Distributed Event Streaming Platform
This distinction matters tremendously.
Key Takeaways
Apache Kafka is:
- a distributed event streaming platform
- built around append-only distributed logs
- designed for scalability and durability
- optimized for high throughput
- capable of real-time stream processing
Kafka became popular because it enables:
- scalable event-driven systems
- asynchronous architectures
- replayable event streams
- distributed resilience
- real-time processing
Kafka is now one of the foundational technologies powering modern distributed systems.