Building Fraud Detection Pipelines with Kafka
Real-Time Fraud Detection Using Event Streaming Architectures
Modern digital systems process enormous volumes of financial activity continuously.
Every second:
- card transactions occur
- UPI payments complete
- wallets transfer money
- login attempts happen
- devices connect
- suspicious activities emerge
Fraud detection systems must analyze these events:
In real time.
Traditional batch-processing systems are often too slow for modern fraud prevention.
By the time nightly fraud analysis completes:
- stolen cards may already be abused
- accounts drained
- money transferred
- damage escalated
This is one of the major reasons organizations increasingly use:
Apache Kafka
to build:
Real-time fraud detection pipelines.
Kafka enables:
- continuous event ingestion
- scalable stream processing
- distributed anomaly detection
- real-time alerting
- replayable fraud analysis
In this article, we will deeply explore:
- how fraud detection systems work
- why Kafka fits fraud architectures
- streaming fraud pipelines
- event correlation
- real-time scoring
- stateful processing
- anomaly detection workflows
- operational considerations
This article demonstrates one of Kafka’s most important real-world use cases.
Why Fraud Detection Is Difficult
Fraud detection is fundamentally:
A streaming data problem.
Fraud systems must continuously analyze:
- transactions
- customer behavior
- login activity
- device patterns
- location anomalies
- velocity spikes
while processing:
- enormous event volumes
- with extremely low latency
Fraud Detection Requires Speed
Suppose stolen card used for:
₹50,000 transaction
If detection occurs:
- 30 minutes later
damage already done.
Modern fraud systems require:
Real-time decision making.
Traditional Batch Fraud Systems
Historically many fraud systems used:
- nightly batch jobs
- periodic analysis
- database reports
Workflow:
Transactions Stored
↓
Nightly Batch Analysis
↓
Fraud Alerts Generated
This approach struggles with:
- latency
- scalability
- immediate response requirements
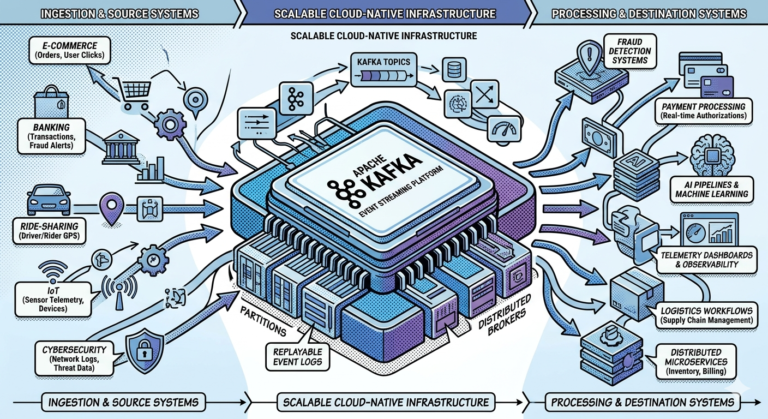
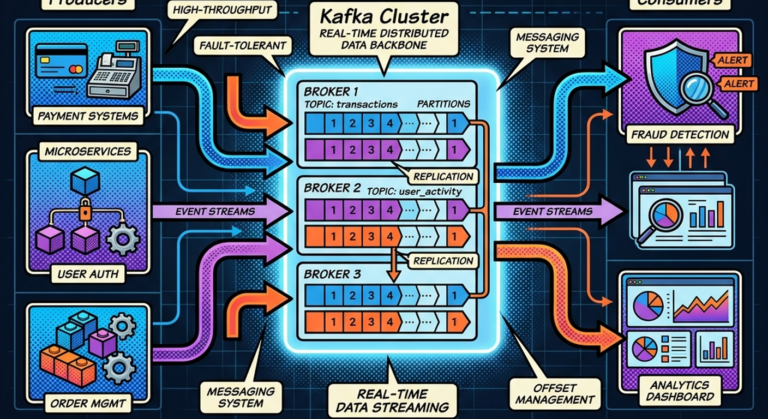
Real-Time Fraud Detection Architecture
Modern systems instead use:
Streaming fraud pipelines.
Kafka architecture:
Transaction Events
↓
Kafka Topics
↓
Fraud Detection Engines
↓
Risk Scores / Alerts
Fraud analysis occurs:
- continuously
- in milliseconds
Why Kafka Fits Fraud Detection Perfectly
Fraud systems require:
- massive scalability
- low latency
- durable event streams
- replayability
- distributed processing
Kafka naturally provides all of these.
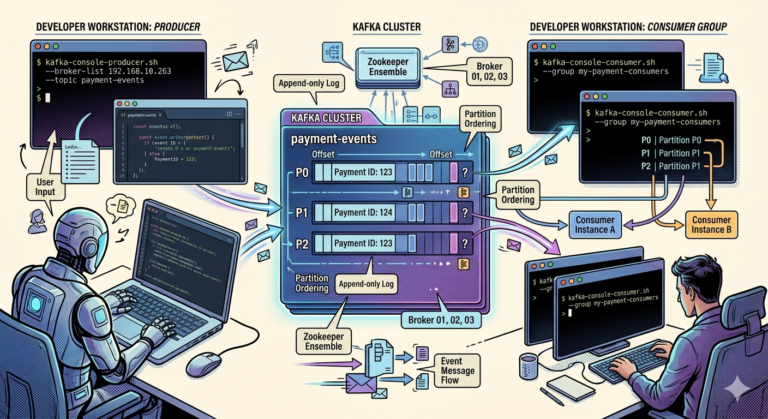
Real-Time Transaction Streaming
Suppose customer payment occurs.
Event generated:
{
"eventType": "PaymentCompleted",
"transactionId": "TXN9001",
"customerId": "CUST100",
"amount": 50000,
"location": "Mumbai"
}
Published into Kafka topic:
payments
Fraud systems immediately consume event.
Fraud Pipelines Consume Streams Continuously
Fraud engine subscribes to:
payments topic
Processes:
- every transaction event
- continuously
- in real time
This enables:
Streaming fraud analysis.
Fraud Detection Is About Pattern Recognition
Individual transactions may appear normal.
Fraud systems often detect:
- suspicious patterns
- abnormal behavior
- correlated anomalies
Kafka streams provide:
- continuous behavioral history
Common Fraud Signals
Fraud systems analyze:
- unusual transaction amounts
- geographic anomalies
- impossible travel patterns
- rapid transaction velocity
- suspicious devices
- repeated failed logins
Example — Velocity Fraud Detection
Suppose customer performs:
20 transactions in 30 seconds
Fraud engine detects:
- abnormal transaction velocity
Generates:
FraudAlert
event immediately.
Example — Geographic Anomaly
Customer normally transacts from:
Bangalore
Suddenly transaction appears from:
Brazil
within 2 minutes.
Fraud pipeline flags:
Impossible travel anomaly.
Stateful Stream Processing
Fraud detection often requires:
Stateful processing.
Meaning:
- systems remember historical activity
Examples:
- previous transactions
- login history
- behavioral baselines
Kafka stream processing enables:
- distributed stateful analytics.
Why Stateful Processing Matters
Fraud decisions often depend on:
- historical context
Not merely:
- current transaction
Example:
Current payment alone looks normal
But combined with:
- prior suspicious behavior
risk becomes high.
Kafka Streams in Fraud Systems
Many organizations use:
Kafka Streams
for:
- real-time fraud analysis
- aggregations
- stateful windows
- event correlation
Example Stream Processing Workflow
Transaction Stream
↓
Window Aggregation
↓
Risk Analysis
↓
FraudAlert Event
Everything happens:
- continuously
- automatically
Windowing in Fraud Detection
Fraud analysis often uses:
Time windows.
Example:
Count transactions
within last 5 minutes
Windows help detect:
- burst activity
- unusual behavior spikes
Event Correlation
Fraud systems correlate:
- login events
- device changes
- transaction attempts
- account updates
Kafka enables:
- cross-stream event correlation
at large scale.
Example Correlated Workflow
Failed Login
↓
Password Reset
↓
Large Transaction
Combined sequence may indicate:
- account takeover attack
Fraud Scoring Pipelines
Fraud systems often compute:
Risk scores.
Example:
| Signal | Risk Contribution |
|---|---|
| Large Amount | +30 |
| New Device | +20 |
| Foreign Location | +40 |
| Rapid Transactions | +25 |
Final:
Fraud Score = 85
Real-Time Decision Engines
Based on fraud score:
| Score Range | Action |
|---|---|
| 0–40 | Allow |
| 41–70 | Additional Verification |
| 71+ | Block Transaction |
Kafka pipelines enable:
- instant decision workflows.
Machine Learning Fraud Models
Modern fraud systems increasingly use:
- machine learning
- anomaly detection
- behavioral AI models
Kafka streams provide:
- continuous model input
for:
- real-time inference pipelines.
Why Replayability Matters in Fraud Systems
Suppose:
- fraud model improves later
Kafka allows:
- replaying historical transactions
- retraining models
- evaluating detection accuracy
This is enormously valuable.
Fraud Investigation Pipelines
Kafka retention enables:
- forensic analysis
- historical replay
- incident reconstruction
Investigators can reconstruct:
- complete transaction timelines
from event history.
Consumer Groups in Fraud Systems
Fraud architectures often use multiple consumer groups:
payments topic
├── Fraud Detection Group
├── Analytics Group
├── Audit Group
└── Settlement Group
Kafka fan-out architecture scales naturally.
Scalability of Fraud Pipelines
Fraud systems may process:
- millions of events per second
Kafka partitions distribute:
- workload horizontally
allowing:
- massive parallel fraud analysis.
Partitioning Strategy
Fraud systems often partition by:
Customer ID
Account ID
Card Number
This preserves:
- behavioral ordering
- state consistency
for related activity.
Why Ordering Matters
Suppose sequence:
Login
Password Change
Large Transfer
Incorrect ordering may:
- hide suspicious behavior
- corrupt fraud analysis
Kafka preserves:
- ordering within partitions
which becomes critical.
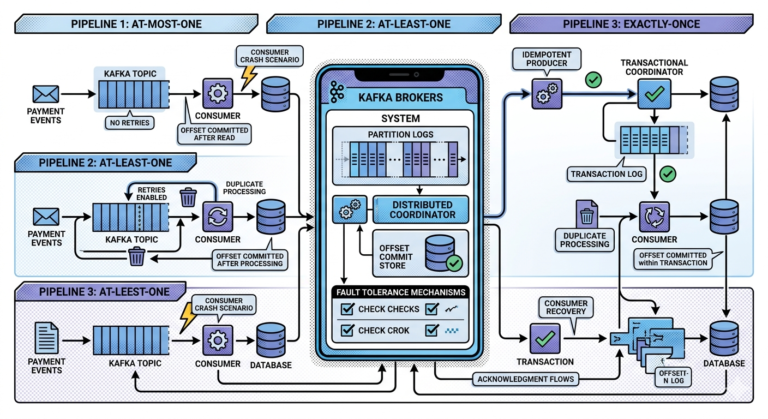
Exactly-Once Challenges in Fraud Pipelines
Fraud systems must avoid:
- duplicate alerts
- repeated blocking actions
Kafka architectures often combine:
- at-least-once delivery
- idempotent consumers
- deduplication logic
for safe processing.
Handling Failures in Fraud Systems
Distributed systems fail regularly.
Examples:
- node crashes
- model service failures
- network interruptions
Kafka retention allows:
- safe retries
- event replay
- consumer recovery
without losing transactions.
Dead Letter Queues (DLQ)
Suppose event processing repeatedly fails.
Kafka architectures often route events into:
fraud-dlq
for:
- manual investigation
- forensic analysis
Fraud Detection Is Never Perfect
Fraud systems constantly balance:
- false positives
- false negatives
Overly aggressive detection:
- blocks legitimate customers
Weak detection:
- misses fraud
Kafka helps provide:
- scalable real-time decision infrastructure
but business logic still matters enormously.
Real-World Fraud Architecture
Many organizations implement:
Transaction Streams
↓
Kafka Topics
↓
Streaming Fraud Engines
↓
Real-Time Risk Decisions
Kafka becomes:
The streaming backbone of fraud intelligence.
Fraud Detection Beyond Payments
Kafka-powered fraud systems also analyze:
- insurance claims
- telecom abuse
- ad click fraud
- account takeovers
- cybersecurity anomalies
Any domain involving:
- high-volume behavioral events
benefits from streaming analytics.
Why Kafka Became So Important in Fraud Systems
Fraud detection requires:
- low latency
- massive scalability
- replayability
- distributed event processing
- continuous analytics
Apache Kafka
provides these capabilities extremely effectively.
This is why Kafka became foundational infrastructure for:
- fintech
- banking
- cybersecurity
- real-time risk platforms
Common Beginner Misconceptions
Misconception 1
Kafka itself detects fraud
Kafka transports and streams events.
Fraud logic lives inside processing systems.
Misconception 2
Fraud detection is only machine learning
Many fraud systems combine:
- rules
- stream processing
- heuristics
- ML models
Misconception 3
Batch fraud analysis is sufficient
Modern fraud increasingly requires:
- real-time streaming detection.
Misconception 4
Replayability is only for debugging
Replay is critical for:
- retraining models
- forensic analysis
- pipeline validation
Key Takeaways
Fraud detection is fundamentally:
- a real-time streaming problem
Kafka enables fraud systems to:
- ingest massive transaction streams
- analyze behavior continuously
- scale horizontally
- replay historical events
- coordinate distributed fraud workflows
Kafka topics stream:
- payments
- logins
- device activity
- customer behavior
into:
- real-time fraud engines
- analytics pipelines
- risk scoring systems
These capabilities make:
Apache Kafka
one of the most important technologies powering modern fraud detection infrastructures.